
The System Behind AI Agents
Một góc nhìn đơn giản hơn về memory, RAG, harness, loop engineering, eval và LLMOps trong cách chúng ta xây dựng AI Agent cho product thật.

Có một giai đoạn mình nghĩ rằng làm việc với AI chủ yếu là học cách prompt tốt hơn, tìm kiếm nhiều prompt template để sử dụng. Prompt rõ hơn, context đầy đủ hơn, format output cụ thể hơn, vậy là model sẽ trả lời tốt hơn.
Điều này đúng, nhưng chỉ đúng ở mức rất cơ bản. Khi bắt đầu nhìn AI dưới góc độ một system có thể vận hành thật sự, đặc biệt là trong môi trường production, trong CRM, trong customer support, trong workflow nội bộ hay trong các hệ thống có dữ liệu và action thật từ user, mình nhận ra prompt chỉ là điểm bắt đầu.
Một AI Agent tốt không phải chỉ là một LLM được gắn thêm vài tool mà nó là một system có trí nhớ, có workflow, có khả năng gọi công cụ, có vòng lặp để hoàn thành task, có điểm dừng, cơ chế quan sát, đánh giá và cải tiến liên tục.
Nói cách khác, vấn đề không còn là “làm sao hỏi AI cho đúng”, mà là “làm sao thiết kế một hệ thống để AI có thể làm việc đúng, ổn định và đáng tin cậy”.
Đây là lý do vì sao gần đây những khái niệm như agent harness, memory system, loop engineering, eval, tracing, LLMOps bắt đầu xuất hiện một cách dày đặc hơn. Nghe qua thì có vẻ giống buzzword, nhưng nếu bóc từng lớp ra, chúng thật ra không quá xa lạ. Với mình, đây là cách ngành phần mềm đang học cách biến một model thông minh nhưng nhiều xác suất thành một hệ thống có thể chạy trong môi trường thật.
Bài viết này mình tham khảo dựa trên một video của một Engineer từ Google cũng như kinh nghiệm của bản thân khi đã triển khai các dự án liên quan tới AI Agents, cùng bắt đầu nhé.
1. AI Agent Run thực sự là gì?
Hãy bắt đầu từ một điều rất cơ bản: AI Agent Run là gì?
Khi bạn hỏi ChatGPT một câu, ví dụ: “OpenClaw ra mắt khi nào?” hay “Large Language Model thực sự là gì?”
Ở tầng đơn giản nhất, đó là một agent run: từ input của user đến output của model.
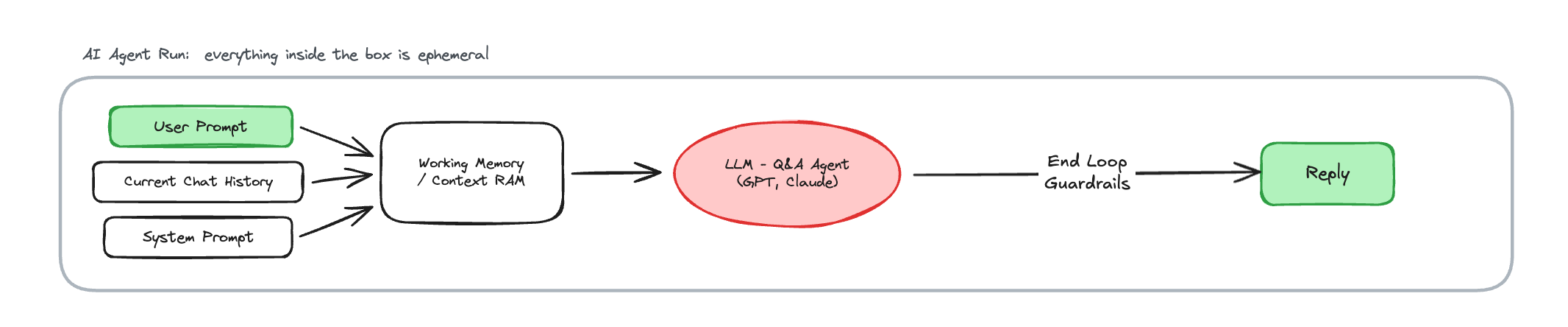
Hình trên mô tả cách bạn sử dụng ChatGPT hay Chatbot AI một cách đơn giản nhất: bạn input một câu hỏi, system sẽ nhận prompt đó, lấy thêm phần chat history hiện tại, cộng với system prompt, rồi đưa tất cả vào model để sinh ra câu trả lời và phản hồi lại cho bạn.
Nhưng vấn đề nằm ở chỗ, mỗi lần chạy này rất ngắn hạn, nó giống như một khoảnh khắc xử lý tạm thời. Model có thể rất thông minh, có thể biết rất nhiều thứ về thế giới, về lịch sử, về khoa học, về lập trình, về kinh doanh, nhưng nó không thật sự biết mình là ai, mình đang làm dự án gì, khách hàng trước đó đã nói gì, policy của công ty là gì, hay workflow cụ thể của business này nên được xử lý ra sao.
Nếu chỉ dựa vào prompt hiện tại và một phần chat history ngắn, agent sẽ luôn bị giới hạn bởi context trước mắt. Nó có thể trả lời tốt trong một cuộc hội thoại đơn lẻ, nhưng rất khó trở thành một hệ thống có khả năng làm việc dài hạn.
Đó là lúc memory trở nên quan trọng.
2. Memory trong AI Agents
Khi nói đến memory của AI, nhiều người thường nghĩ đơn giản là lưu lại chat history. Nhưng nếu nhìn kỹ hơn, memory trong một agent system có thể được chia thành nhiều lớp khác nhau.
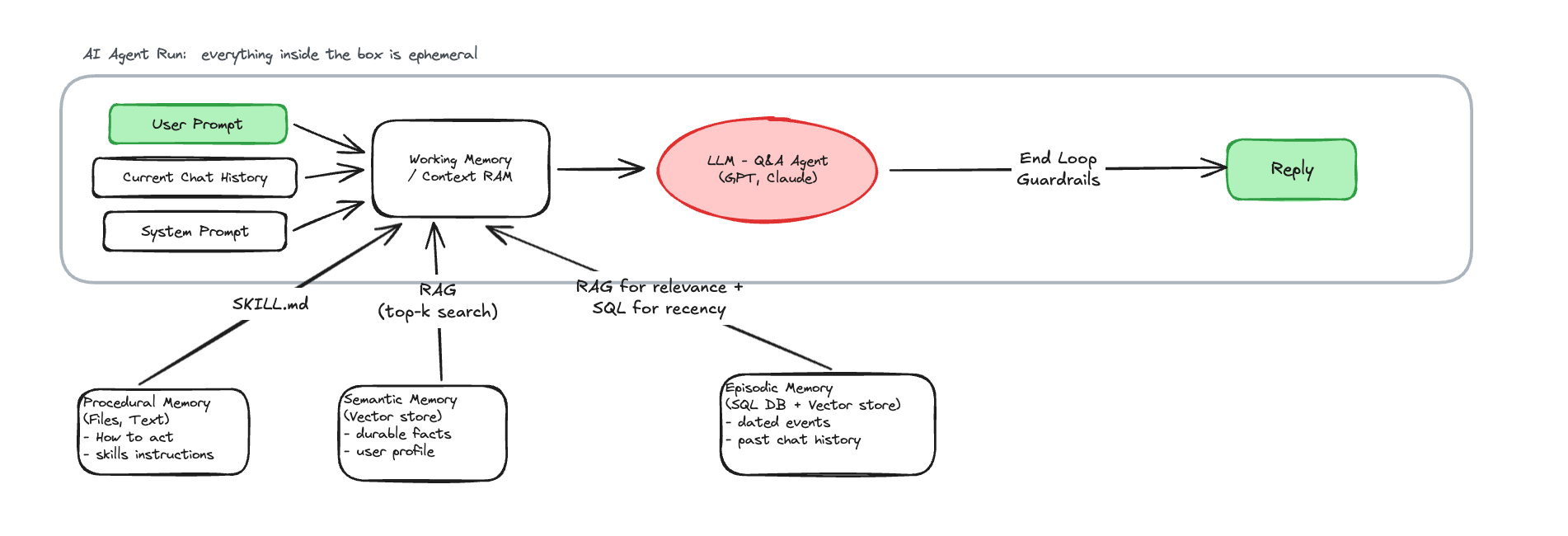
Lớp đầu tiên là procedural memory: Đây là phần nói cho agent biết nó nên hành động như thế nào, nó giống như một bộ SOP hoặc instruction manual. Agent nên trả lời theo tone nào, nên xử lý task theo quy trình nào, khi nào được gọi tool, khi nào phải hỏi lại user, khi nào phải trả về format cụ thể. Trong nhiều hệ thống hiện nay, phần này có thể nằm trong system prompt, file markdown, nếu bạn sử dụng Claude thì nó có thể là file CLAUD.md hoặc những thứ được gọi Skills, và hiện nay có rất nhiều skill được tạo ra để phục vụ cho các hệ thống Agents này làm việc một cách hiệu quả.
Lớp thứ hai là semantic memory: Đây là những sự thật tương đối ổn định mà agent nên biết. Ví dụ, mình là ai, mình đang làm sản phẩm nào, công ty có những policy nào, khách hàng thuộc nhóm nào, một feature đang có rule gì, hay một business đang vận hành theo logic nào. Đây không phải là lịch sử hội thoại đơn thuần, mà là những “durable facts” giúp agent hiểu bối cảnh dài hạn. Trong thực tế, thì mình sẽ cần một DB hoặc memory store cho phần này, mục tiêu để agent có thể retrieve khi cần, điều quan trọng nó là nơi chứa những fact đã được chắt lọc và có giá trị dài hạn.
Lớp thứ ba là episodic memory: Đây là lịch sử sự kiện theo thời gian. Một khách hàng đã từng complaint những gì, lần gần nhất team follow-up là khi nào, user đã từng hỏi gì trong những cuộc trò chuyện trước, một case đã được xử lý qua những bước nào. Nó giống như một dòng thời gian của các sự kiện, có timestamp, có ngữ cảnh, có diễn biến.
Ba loại memory này giải quyết ba câu hỏi khác nhau.
Procedural memory trả lời câu hỏi: agent nên hành động như thế nào?
Semantic memory trả lời câu hỏi: agent nên biết những sự thật ổn định nào?
Episodic memory trả lời câu hỏi: điều gì đã từng xảy ra trước đây?
Nếu thiếu ba lớp này, agent sẽ giống một nhân sự rất thông minh nhưng mỗi ngày đi làm lại bị mất trí nhớ. Người đó có thể suy luận tốt, nhưng không biết team đang làm gì, khách hàng là ai, chuyện gì đã xảy ra hôm qua, và quy trình công ty yêu cầu xử lý như thế nào.
Đây cũng là kinh nghiệm khi mình tổ chức triển khai các hệ thống Agents, ban đầu mình nghĩ rằng memory đơn giản là lưu lại càng nhiều càng tốt nhưng khi đi vào thiết kế vận hành thật thì vấn đề sẽ khác hoàn toàn. Không phải data nào cũng nên trở thành memory, không phải conversation nào cũng cần được lưu dài hạn và cũng không phải fact nào agent cũng nên tự động tin tưởng nếu chưa có source of truth rõ ràng.
3. Agent Harness giúp kiểm soát LLM
Một hình ảnh mình thấy khá dễ hiểu là xem LLM như một chiếc xe đua F1 vậy.
Bản thân chiếc xe có động cơ rất mạnh, có thể tăng tốc cực nhanh và tạo ra hiệu suất vượt xa một chiếc xe thông thường. Nhưng nếu chỉ có động cơ mạnh thôi thì chưa đủ để chiến thắng một cuộc đua. Xe cần vô lăng, phanh, bộ điều khiển, chiến thuật pit stop, cảm biến telemetry, đội kỹ thuật theo dõi phía sau và một tay đua biết rõ mình đang ở khúc cua nào, nên tăng tốc lúc nào, nên giảm tốc lúc nào.
LLM cũng tương tự. Model có năng lực rất lớn, nhưng nếu không có lớp kiểm soát xung quanh, nó có thể trả lời sai context, gọi nhầm tool, làm quá phạm vi, hoặc tiếp tục chạy một workflow dù đáng lẽ phải dừng lại để hỏi user. Nó có thể “chạy nhanh”, nhưng trong sản phẩm thật, chạy nhanh không quan trọng bằng việc chạy đúng hướng, đúng luật và có thể kiểm soát được khi có vấn đề xảy ra.
Đây là ý nghĩa của agent harness.
Harness là toàn bộ lớp kiểm soát được xây quanh LLM để đảm bảo model hoạt động theo cách mình muốn. Nó bao gồm system prompt, memory, retrieval, tool calling, loop, guardrails, permission, logging, evaluation và nhiều thành phần khác.
Điểm quan trọng là harness không làm LLM thông minh hơn theo nghĩa model biết thêm tất cả mọi thứ. Harness giúp sức mạnh của LLM được đặt trong một cấu trúc có kiểm soát. Thay vì để model tự đoán nên làm gì, hệ thống sẽ hướng dẫn nó lấy context nào, dùng tool nào, tuân thủ rule nào, khi nào cần hỏi lại user, và khi nào nên dừng.
Trong môi trường sản phẩm, đây là khác biệt rất lớn giữa một demo ấn tượng và một hệ thống có thể chạy thật.
Một demo AI có thể gây bất ngờ vì trả lời hay nhưng một AI Agent trong production cần nhiều hơn thế. Nó cần ổn định, có thể debug, có thể kiểm soát chi phí, có thể đo lường chất lượng, và quan trọng nhất là không được tự ý làm những việc vượt quá quyền hạn.
4. Memory cần được lưu, cập nhật và chắt lọc
Một điểm mình thấy nhiều người dễ bỏ qua là memory không tự nhiên xuất hiện.
Nếu muốn agent có trí nhớ, mình cần một nơi để lưu nó, có thể là database, vector store, file system, data warehouse, hoặc một kiến trúc kết hợp nhiều nguồn khác nhau. Nhưng lưu thôi vẫn chưa đủ, system còn cần biết memory nào nên được ghi lại, memory nào nên được cập nhật, memory nào nên bị bỏ qua, và memory nào nên được chắt lọc thành tri thức ổn định hơn.
Ví dụ trong một hệ thống customer support cho e-commerce, khách hàng có thể hỏi hàng nghìn lần về refund, đổi trả, giao hàng, lỗi sản phẩm. Nếu lưu toàn bộ hội thoại một cách thô, hệ thống sẽ nhanh chóng trở nên rất lớn, tốn kém và khó retrieve chính xác.
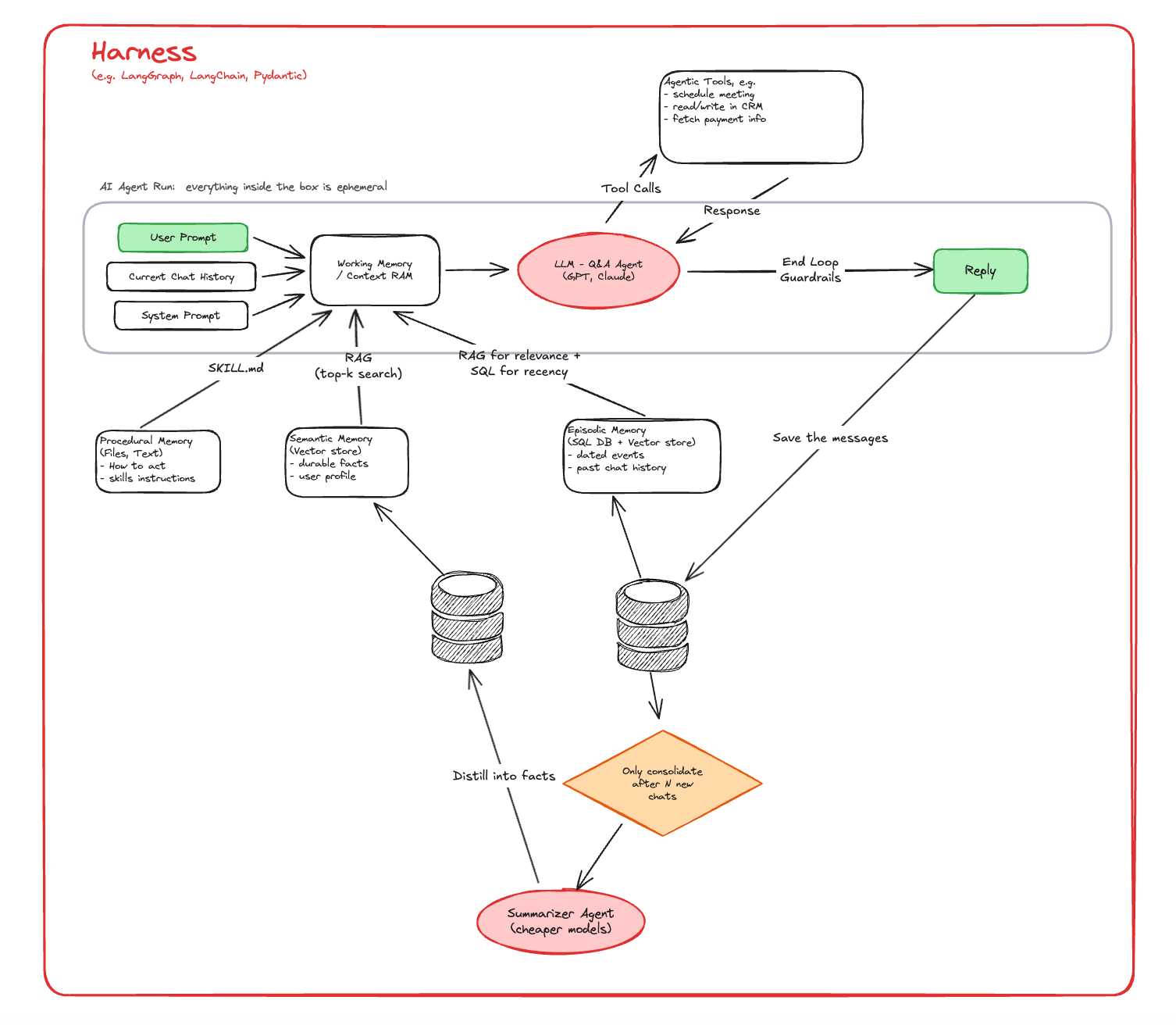
Một cách tốt hơn là sau một số lượng conversation nhất định, hệ thống có thể đưa các đoạn hội thoại này qua một summarizer agent để chắt lọc thành semantic memory. Thay vì phải đọc lại một triệu cuộc trò chuyện, agent có thể biết một fact đã được tổng hợp:
“Khách hàng thường hỏi về hoàn tiền khi sản phẩm lỗi. Quy trình hiện tại là kiểm tra order, xác nhận tình trạng sản phẩm, sau đó chuyển sang payment system để xử lý refund nếu đủ điều kiện.”
Từ một chuỗi sự kiện rời rạc, hệ thống tạo ra tri thức có cấu trúc hơn.
Sự kết hợp này khá phù hợp để Agent có thể tiếp thu thêm tri thức sau những đoạn hội thoại từ khách hàng, từ đó tiếp tục tái sử dụng cho những conversation trong tương lai. Đây là điều khiến AI Agent khác với một chatbot thông thường. Nó không chỉ phản hồi từng câu hỏi, mà có thể dần dần xây dựng một lớp hiểu biết về user, business và workflow.
5. Retrieval không phải lúc nào cũng là RAG
Khi nói về AI Agent, người ta thường nhắc đến RAG như một giải pháp mặc định cho retrieval. Nhưng thực tế, RAG chỉ là một phần trong bức tranh lớn hơn.
Với semantic memory, RAG rất hữu ích, nếu dữ liệu là policy, document, knowledge base, mô tả sản phẩm, hoặc các đoạn text dài, semantic search giúp agent tìm được phần nội dung có ý nghĩa gần với câu hỏi của user.
Hiểu một cách đơn giản, semantic search là cách tìm kiếm theo ý nghĩa thay vì chỉ tìm đúng keyword. Ví dụ user hỏi “khách hàng không hài lòng về việc delivery”, system vẫn có thể tìm ra các đoạn hội thoại dùng những cách diễn đạt như “ship quá lâu”, “đợi mãi chưa nhận được hàng” hay “delivery bị delay”, vì các câu này có ý nghĩa gần nhau.
RAG là bước tiếp theo sau semantic search, system sẽ dùng semantic search để lấy những đoạn thông tin liên quan nhất từ database, document hoặc memorty store, sua đó đưa các đoạn đó vào context cho LLM trước khi model trả lời.
Nhưng không phải mọi dữ liệu đều nên retrieve bằng RAG.
Nếu user hỏi: “10 cuộc trò chuyện gần nhất với khách hàng này là gì?”, câu trả lời tốt nhất có thể đến từ một SQL query rất rõ ràng theo customer_id và timestamp.
Nếu user hỏi: “Khách hàng này có bao nhiêu order chưa thanh toán?”, agent nên gọi API hoặc query database có cấu trúc.
Nhưng nếu user hỏi: “Trong 20 cuộc trò chuyện gần đây, có case nào khách hàng phàn nàn về chất lượng sản phẩm nhưng agent chưa xử lý thành công không?”, lúc này chỉ SQL có thể chưa đủ. Hệ thống cần vừa lọc theo customer, thời gian, status, vừa dùng semantic search để hiểu nội dung complaint trong text.
Điều này dẫn tới một insight quan trọng: một agent tốt không nên chỉ biết RAG. Nó cần biết chọn đúng cách retrieve theo từng loại dữ liệu.
Thông thường thì dữ liệu có cấu trúc thì dùng SQL hoặc API còn dữ liệu không có cấu trúc thì dùng semantic search.
Câu hỏi phức tạp thì cần kết hợp cả hai.
Với góc nhìn của mình, đây không đơn thuần là vấn đề kỹ thuật mà đây là vấn đề thiết kế luồng thông tin. Agent cần gì để ra quyết định đúng? Dữ liệu đó nằm ở đâu? Nên lấy bằng cách nào? Và lấy bao nhiêu là đủ?
6. Khi agent bắt đầu hành động, câu hỏi không còn là nó thông minh đến đâu
Điểm thú vị của AI Agent không nằm ở việc nó trả lời hay hơn chatbot. Điều khiến agent trở nên khác biệt là nó có thể bước ra khỏi phạm vi hội thoại và bắt đầu hành động trong một hệ thống thật.
Một chatbot có thể nói với mình rằng nên follow-up với khách hàng A. Nhưng một agent, nếu được kết nối đúng cách, có thể đọc lịch sử trong CRM, kiểm tra khách hàng đó đã complaint bao nhiêu lần, xem refund đã được xử lý chưa, tạo task cho sales, draft một email follow-up, hoặc thậm chí trigger một workflow trong payment system.
Đây là lúc AI bắt đầu có giá trị vận hành, nhưng cũng là lúc rủi ro tăng lên rất nhanh. Nếu agent trả lời sai một đoạn text, mình có thể sửa lại nhưng nếu agent gửi nhầm email, update sai CRM, refund nhầm khách hàng hoặc trigger một chuỗi action không cần thiết, hậu quả không còn nằm trong phạm vi “AI trả lời chưa tốt” nữa mà nó đã trở thành vấn đề của business logic, permission, audit trail và trách nhiệm vận hành.
Vì vậy, khi agent có khả năng gọi tool, câu hỏi quan trọng không còn là “model có đủ thông minh không”, mà là “hệ thống có đủ kiểm soát để model hành động đúng không”.
7. Loop Engineering thật ra rất gần với workflow design
Một task trong business hiếm khi chỉ có một bước, khi user hỏi: “Giúp tôi tìm những khách hàng đang complain về sản phẩm trong hai tháng gần đây, xem ai chưa được refund, và đề xuất cách follow-up để kéo họ quay trở lại”, agent không thể chỉ đọc một document rồi trả lời ngay.
Nó cần đi qua nhiều bước. Trước tiên, nó phải đọc dữ liệu trong CRM để tìm các complaint liên quan. Sau đó, nó phải phân loại complaint nào thật sự liên quan đến chất lượng sản phẩm, complaint nào đã được xử lý, complaint nào vẫn còn pending. Tiếp theo, nó có thể cần kiểm tra payment system để biết refund đã được thực hiện hay chưa. Chỉ sau khi ghép được các mảnh dữ liệu này lại với nhau, agent mới có đủ context để đề xuất một hướng follow-up hợp lý.
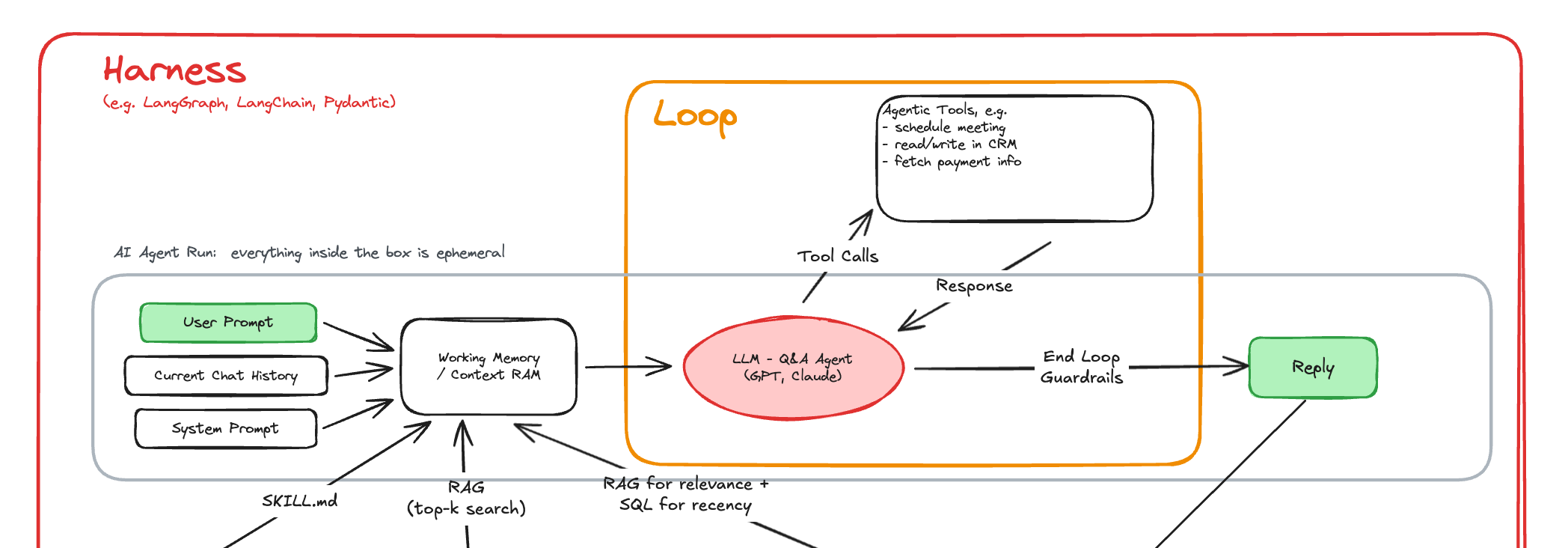
Chuỗi hành động đó chính là loop.
Agent suy nghĩ, gọi tool, nhận kết quả, đánh giá xem kết quả đã đủ chưa, rồi tiếp tục gọi tool hoặc dừng lại để trả lời user. Nếu nhìn từ bên ngoài, đây có vẻ là một khái niệm kỹ thuật, nhưng với mình, loop engineering thật ra rất gần với cách một PM hoặc BA thiết kế workflow. Mình vẫn phải trả lời những câu hỏi quen thuộc: task này gồm những bước nào, bước nào cần dữ liệu, bước nào cần gọi hệ thống khác, bước nào cần human approval, và khi nào thì một workflow được xem là hoàn tất.
Điểm khác biệt là trước đây workflow thường được hard-code bằng rule rõ ràng, còn với AI Agent, một phần quyết định được giao cho model. Chính vì vậy, loop càng linh hoạt thì guardrail càng phải chặt.
8. Một agent tốt không phải là agent làm mọi thứ, mà là agent biết khi nào nên dừng
Khi nói về autonomous agent, chúng ta rất dễ bị hấp dẫn bởi ý tưởng một hệ thống có thể tự làm mọi thứ từ đầu đến cuối. Nhưng trong thực tế sản phẩm, mức độ tự động hóa càng cao thì nhu cầu kiểm soát càng lớn.
Một agent đáng tin cậy không phải là agent luôn cố làm thêm bước tiếp theo. Nó là agent hiểu rõ điểm dừng của mình nằm ở đâu.
Nếu user hỏi “ai là những khách hàng chưa được refund?”, agent nên trả về danh sách và giải thích cơ sở dữ liệu mà nó dùng để xác định. Nếu user hỏi “đề xuất cách xử lý các khách hàng này”, agent nên đưa ra phương án follow-up, có thể kèm theo draft email hoặc task suggestion. Nhưng nếu user nói “hãy refund cho họ”, agent cần hiểu rằng đây là một hành động có impact tài chính, và tùy vào rule của hệ thống, nó có thể phải xin xác nhận trước khi thực hiện.
Đây là vai trò của end-loop guardrails. Nó giúp agent biết khi nào task đã đủ điều kiện hoàn tất, khi nào cần hỏi lại user, khi nào chỉ nên đề xuất thay vì thực thi, và khi nào một hành động vượt quá quyền hạn của nó.
Một nguyên tắc mình thấy hữu ích là tách rõ read action và write action. Những hành động như đọc CRM, kiểm tra lịch sử conversation, truy xuất trạng thái payment thường có thể tự động nhiều hơn, vì rủi ro thấp hơn. Nhưng những hành động như gửi email, cập nhật CRM, hoàn tiền, xóa dữ liệu hoặc tạo transaction thì cần được kiểm soát chặt hơn.
Agent càng có nhiều quyền, hệ thống càng cần biết cách nói “dừng lại”.
9. Khi agent chạy sai, mình cần biết nó sai ở đâu
Sau khi đã có memory, retrieval, tool calling và loop, một vấn đề khác bắt đầu xuất hiện: làm sao biết agent đang chạy tốt hay không?
Trong một demo, mình có thể đọc output cuối cùng và cảm nhận rằng câu trả lời có vẻ ổn. Nhưng trong production, cảm giác đó là không đủ, một agent run có thể bao gồm nhiều bước retrieve, nhiều lần gọi tool, nhiều quyết định trung gian và nhiều phần context được đưa vào model. Nếu chỉ nhìn câu trả lời cuối cùng, mình sẽ rất khó biết hệ thống sai ở đâu khi có vấn đề xảy ra.
Agent có thể sai vì prompt chưa rõ hoặc nó cũng có thể sai vì retrieve nhầm document, vì memory đã cũ, vì tool call bị fail, vì context quá dài, hoặc vì loop không biết dừng đúng lúc. Tất cả những lỗi này có thể dẫn đến một output cuối cùng không đạt yêu cầu, nhưng cách sửa mỗi lỗi lại hoàn toàn khác nhau.
Đây là lý do tracing trở nên quan trọng. Tracing cho mình khả năng nhìn vào bên trong mỗi lần agent chạy, giống như mở hộp đen của hệ thống. Mình có thể thấy user đã hỏi gì, agent đã lấy memory nào, gọi tool bao nhiêu lần, tool nào thành công, tool nào thất bại, response time mất bao lâu, token cost là bao nhiêu, và output cuối cùng được tạo ra từ những context nào.
Không có tracing, debug AI Agent gần giống như đoán mò. Có tracing, mình bắt đầu có đủ dữ liệu để hiểu vấn đề thật sự nằm ở đâu.
10. Eval là cách biến cảm giác có vẻ ổn thành tiêu chí đo được
Tracing giúp mình quan sát, nhưng quan sát thôi chưa đủ. Sau khi biết một agent run đã diễn ra như thế nào, mình vẫn cần đánh giá xem lần chạy đó có tốt không.
Đó là vai trò của eval.
Một phần eval có thể được viết bằng rule rất rõ ràng. Nếu task là tạo meeting, meeting có được tạo thành công không? Nếu agent gọi API, API có trả về success không? Nếu hệ thống yêu cầu latency dưới năm giây, response time có vượt ngưỡng không? Nếu team đặt budget token cho mỗi run, lần chạy này có đang quá đắt không?
Nhưng cũng có những phần eval khó đo bằng rule cứng. Câu trả lời có thật sự đúng intent của user không? Agent có bỏ sót thông tin quan trọng không? Nó có hallucination không? Nó có đề xuất một hành động vượt quá quyền hạn không? Trong những trường hợp này, team có thể dùng LLM-as-judge để đánh giá output dựa trên rubric đã định nghĩa trước.
Với mình, eval nên được nhìn giống test case trong software. Nếu xây customer support agent, mình cần eval cho refund, complaint, angry customer, missing information, escalation to human và policy conflict. Nếu xây CRM assistant, mình cần eval cho lead assignment, duplicate detection, customer history, sales follow-up và permission. Mỗi lần đổi prompt, đổi model, đổi retrieval strategy hoặc thêm tool mới, team nên chạy lại eval để biết hệ thống đang tốt hơn hay tệ đi.
Đây là điểm khác biệt giữa việc thử nghiệm AI và xây một AI product nghiêm túc.
11. LLMOps là vòng lặp cải tiến phía sau một agent
Khi tracing và eval được đặt cạnh nhau, mình bắt đầu có một vòng vận hành đầy đủ hơn cho AI Agent. Mỗi lần agent chạy, hệ thống ghi lại toàn bộ trace, sau đó, eval đánh giá chất lượng của run đó, từ độ đúng, độ an toàn, latency cho đến chi phí. Nếu có vấn đề, team có thể diagnose nguyên nhân và quyết định nên sửa ở đâu: prompt, model config, retrieval, memory, tool, guardrail hay business logic.
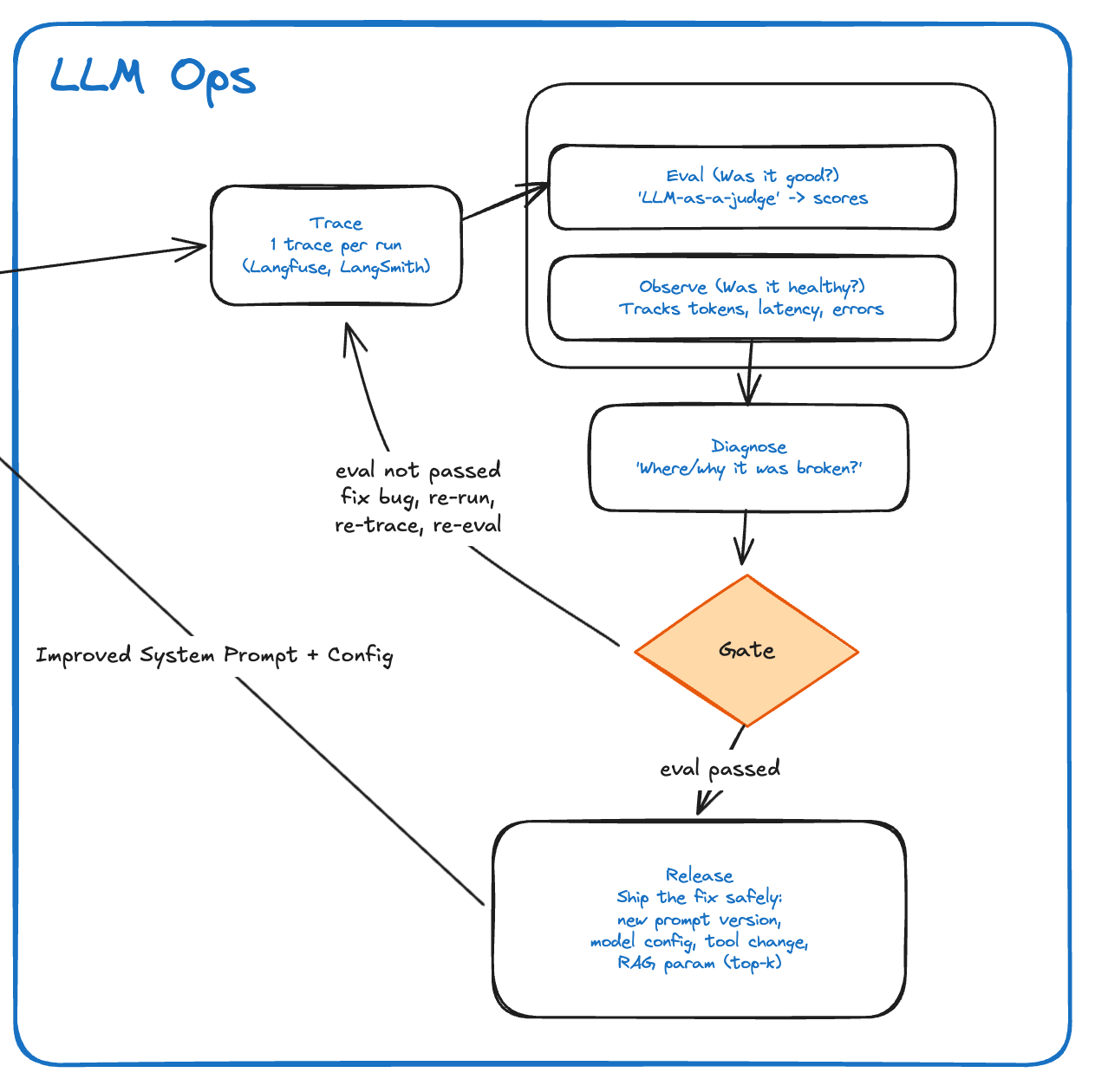
Đây là phần mình thấy LLMOps trở nên quan trọng. Nó không chỉ là một dashboard để nhìn số liệu, mà là cách giúp AI Agent được vận hành như một hệ thống sản phẩm thật. Team không chỉ hỏi “agent trả lời có hay không”, mà hỏi sâu hơn: nó có ổn định không, có đắt quá không, có bị chậm không, có gọi đúng tool không, có retrieve đúng context không, và sau mỗi lần sửa, chất lượng có thật sự cải thiện không.
Nếu lỗi nhỏ và ít rủi ro, team có thể cập nhật prompt hoặc điều chỉnh một vài tham số retrieval. Nhưng nếu lỗi nằm ở logic sâu hơn, chẳng hạn tool call sai, permission thiếu, hoặc workflow chưa rõ, thì vấn đề cần được đưa về development, fix đúng cách, test lại và release có kiểm soát.
Vì vậy, khi nói agent system có thể self-evolve, mình không hiểu điều đó theo nghĩa để AI tự do sửa production. Trong sản phẩm thật, self-evolving nên được hiểu là hệ thống có khả năng học từ dữ liệu vận hành, đề xuất cải tiến và giúp team iterate nhanh hơn, nhưng vẫn nằm trong một vòng kiểm soát rõ ràng.
12. Điều này thay đổi cách mình nghĩ về product design
Điều làm mình quan tâm nhất ở AI Agent không phải là việc có thêm vài thuật ngữ mới. Điều quan trọng hơn là nó buộc mình nghĩ lại về cách thiết kế sản phẩm.
Trước đây, khi viết requirement cho một feature, mình thường nghĩ về màn hình, API, database, permission, workflow và edge case, etc. yên tâm là những thứ đó vẫn còn nguyên giá trị. Nhưng với AI Agent, mình phải thêm một lớp mới: agent sẽ suy nghĩ và hành động như thế nào bên trong workflow này?
Agent cần biết gì trước khi xử lý task? Dữ liệu nào là fact ổn định, dữ liệu nào là lịch sử sự kiện? Nó nên retrieve từ document, database hay API? Nó được phép gọi tool nào? Tool nào cần user approve? Khi nào agent nên hỏi lại? Khi nào output được xem là đúng? Và nếu agent sai, mình sẽ đo, trace và debug bằng cách nào?
Những câu hỏi này khiến requirement cho AI Agent không thể chỉ dừng ở mức “AI trả lời câu hỏi của user”. Một requirement tốt cần mô tả intent, context, memory, tool access, permission, điểm dừng, failure mode và tiêu chí đánh giá.
Nếu không làm rõ các phần này, team rất dễ tạo ra một agent nhìn thì thông minh trong demo, nhưng lại khó kiểm soát khi chạy trong môi trường thật.
13. Từ chatbot đến một hệ thống biết vận hành
Điểm mình rút ra sau cùng là AI Agent không nên được hiểu như một chatbot nâng cấp. Chatbot chủ yếu giao tiếp, còn agent không chỉ giao tiếp mà còn ghi nhớ, truy xuất dữ liệu, gọi công cụ, đi qua nhiều bước xử lý, đưa ra quyết định trong giới hạn và được quan sát để cải tiến liên tục.
Để làm được điều đó, LLM chỉ là phần lõi, xung quanh nó cần một hệ thống harness đủ tốt. Memory giúp agent có bối cảnh dài hạn. Retrieval giúp agent lấy đúng thông tin. Tool calling giúp agent hành động. Loop engineering giúp agent hoàn thành task qua nhiều bước. Guardrails giúp agent biết giới hạn. Tracing giúp team nhìn thấy bên trong mỗi lần chạy. Eval giúp đo chất lượng. LLMOps giúp hệ thống được cải tiến sau mỗi vòng vận hành.
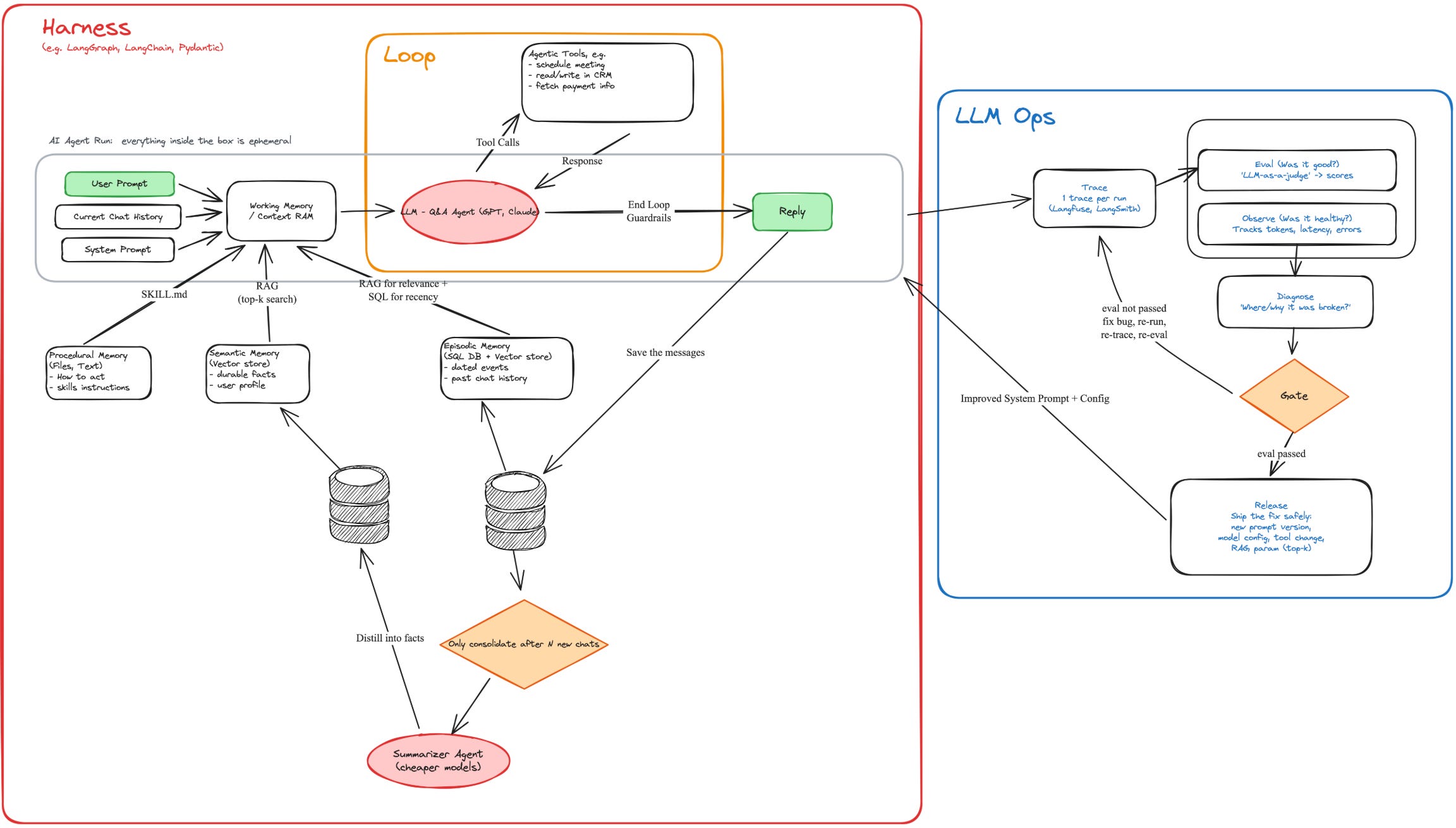
Khi nhìn theo cách này, những buzzword như harness, loop engineering, eval hay LLMOps không còn quá xa lạ. Chúng là cách ngành công nghệ đang đặt lại nền móng để đưa AI từ demo vào production.
Và có lẽ đây cũng là thay đổi lớn nhất: trong thế giới AI Agent, giá trị không chỉ nằm ở việc chọn model nào mạnh hơn, mà nằm ở việc thiết kế một hệ thống đủ tốt để model đó có thể làm việc đúng cách.
Một model mạnh nhưng không có harness sẽ giống một con ngựa khỏe nhưng không có dây cương. Nó có thể chạy rất nhanh, nhưng sản phẩm thật không chỉ cần tốc độ. Sản phẩm thật cần một hệ thống biết mình đang đi đâu, đi bằng cách nào, khi nào nên tăng tốc, khi nào nên dừng lại, và làm sao để sau mỗi lần chạy, nó trở nên tốt hơn một chút.
14. Lời Kết
Bài viết này khá dài, nhưng mình đã cố gắng đơn giản hóa mọi thứ nhiều nhất có thể, vì mình tin rằng để hiểu AI Agent, chúng ta không nhất thiết phải bắt đầu bằng những thuật ngữ quá kỹ thuật. Đôi khi chỉ cần nhìn nó như một hệ thống sản phẩm: có context, có memory, có workflow, có permission, có điểm dừng, có cách đo lường và có vòng lặp cải tiến.
Nếu bạn đã đọc tới đây, cảm ơn bạn rất nhiều vì đã dành thời gian. Hy vọng bài viết này mang lại cho bạn một vài góc nhìn hữu ích, hoặc ít nhất giúp những khái niệm như memory, RAG, harness, loop engineering, eval và LLMOps trở nên dễ hình dung hơn một chút.
Với mình, đây mới là nền tảng thật sự của AI Agent: không chỉ là một model thông minh, mà là một hệ thống biết vận hành, biết kiểm soát và biết học tốt hơn qua từng vòng sử dụng.