
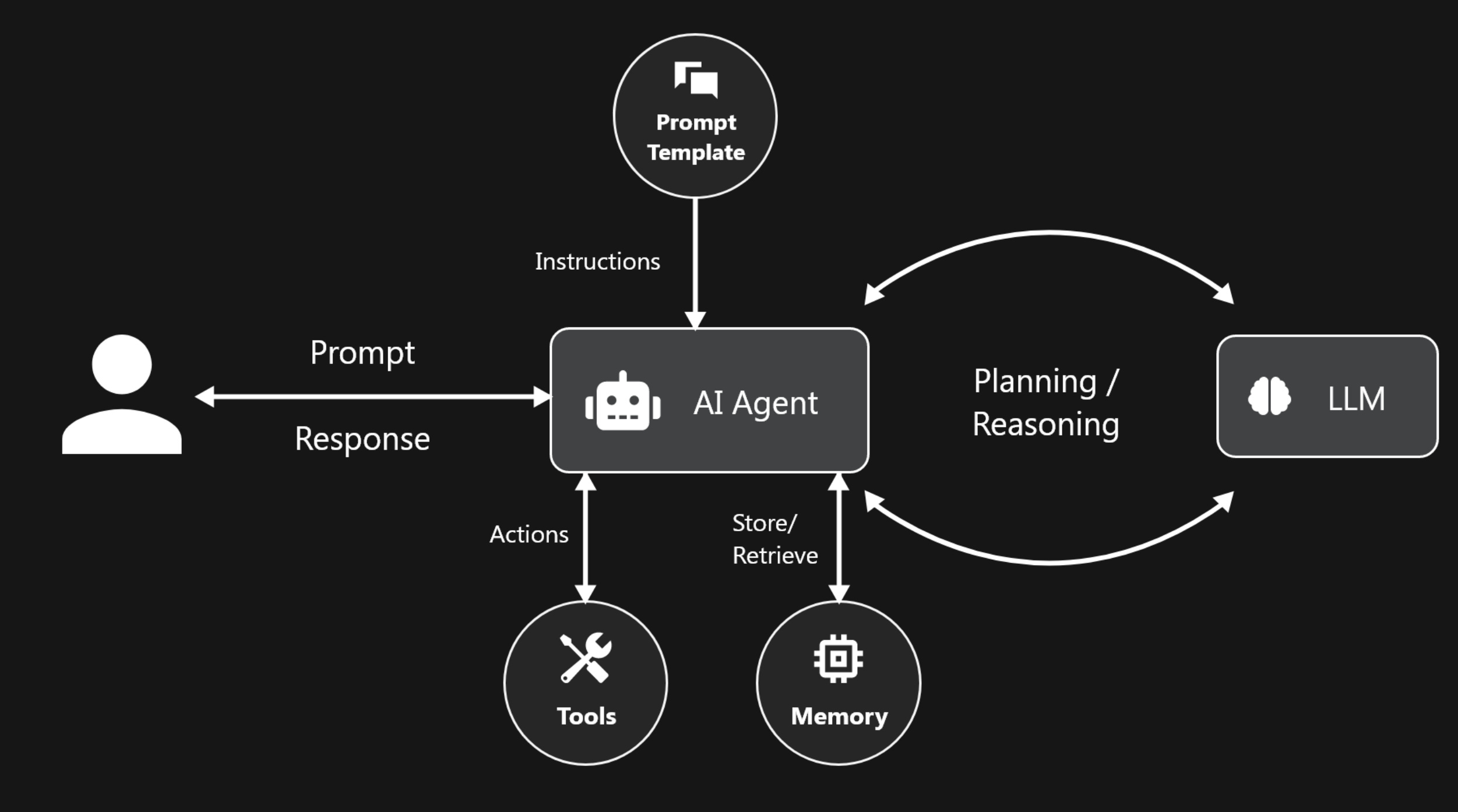
Scaling Law
Vì sao AI không chỉ thông minh lên vì model to hơn

Có một thời gian, cách mọi người hiểu về AI rất đơn giản
cứ tăng model size, tăng data, tăng compute
thì model sẽ thông minh hơn.
Nhìn ở mức rất rộng thì điều đó đúng. Và chính niềm tin này đã tạo ra cả một kỷ nguyên LLM. Nhưng nếu dừng ở đó, ta sẽ bỏ lỡ phần thú vị nhất của câu chuyện.
Vì hôm nay, Scaling Law không còn chỉ là câu chuyện của việc train một model lớn hơn. Nó đã trở thành câu chuyện của nhiều lớp mở rộng chồng lên nhau: từ pre-training, sang post-training, sang test-time compute, và gần đây hơn là cách cả một hệ thống agent phối hợp với nhau để giải quyết công việc. Các paper kinh điển của OpenAI và DeepMind đặt nền móng cho khái niệm scaling, còn các công bố gần đây từ OpenAI và NVIDIA cho thấy scale đang dần chuyển từ bài toán model sang bài toán inference và system design. [1]
1. Scaling Law thực ra là gì?
Nói đơn giản, scaling law là một quy luật thực nghiệm cho thấy khi tăng một số yếu tố như số tham số của model, lượng dữ liệu huấn luyện và tài nguyên tính toán, thì hiệu năng của model sẽ cải thiện theo một quy luật khá ổn định, thường được mô tả gần đúng bằng power law. Trong paper năm 2020, OpenAI cho thấy loss của language model giảm theo quy luật dạng lũy thừa khi tăng model size, dataset size và compute, và xu hướng này giữ được trên nhiều bậc độ lớn khác nhau. [1]
Điều này quan trọng vì nó biến tiến bộ AI từ cảm giác thử và sai thành thứ gì đó có thể dự đoán. Thay vì chỉ hy vọng rằng model lớn hơn sẽ tốt hơn, các nhóm nghiên cứu có thể ước lượng khá rõ: nếu tăng compute thêm, hoặc thay đổi cách phân bổ compute giữa model và data, ta có thể kỳ vọng mức cải thiện nào. Đó là lý do scaling law không chỉ là một khái niệm nghiên cứu, mà còn là nền tảng cho chiến lược đầu tư của các lab AI lớn. [2]
2. Quy luật gốc: pre-training scaling
Nếu phải chọn một phiên bản đầu tiên của scaling law trong thời đại LLM, thì đó là pre-training scaling.
Đây là logic đã mở đường cho GPT, Claude, Gemini, Llama và nhiều foundation model khác: tăng quy mô dữ liệu huấn luyện, tăng số tham số, tăng compute, rồi quan sát model ngày càng mạnh lên. NVIDIA mô tả đây là “original law of AI development”, còn paper của OpenAI năm 2020 là một trong những nền tảng học thuật nổi bật cho cách nhìn này [1][3].
Ở tầng này, trực giác khá rõ:
Model lớn hơn học được nhiều pattern phức tạp hơn
Data nhiều hơn giúp model tổng quát hóa tốt hơn
Compute lớn hơn cho phép huấn luyện ở quy mô cao hơn
Chính pre-training scaling đã tạo ra cú nhảy từ các mô hình NLP cũ sang frontier models ngày nay. Nhưng cũng từ đây, ngành AI bắt đầu va vào một câu hỏi rất thực tế: có phải cứ làm model to hơn là luôn đúng không? [3]
Hãy nhớ hình này nhé, vì phía sau mình sẽ phân tích các level scaling, nó là một bức tranh rất trực quan để hiểu rõ Scaling Law trong kỷ nguyên AI này.
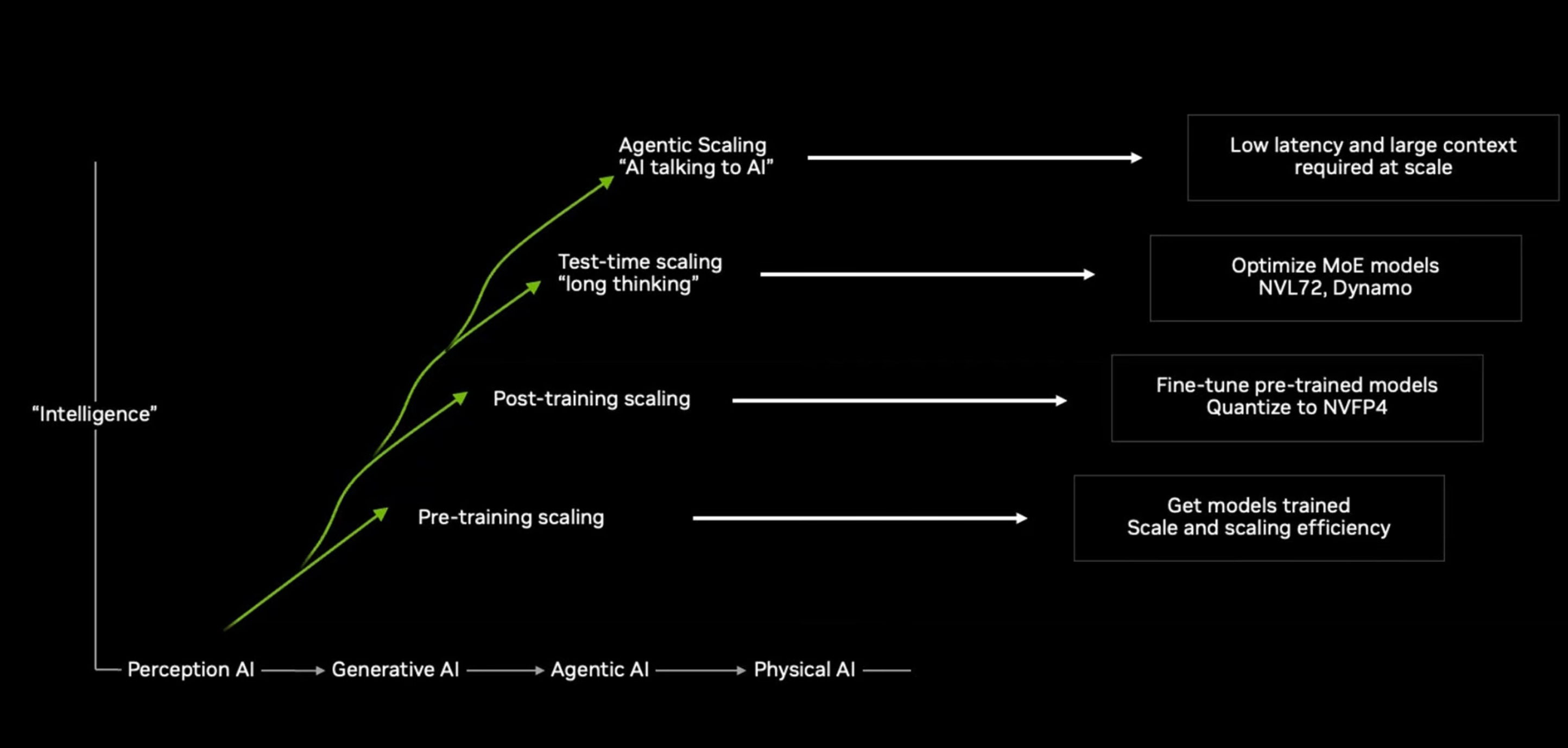
3. Chinchilla đã thay đổi cách ngành AI nghĩ về scale
Một trong những đóng góp quan trọng nhất sau paper của OpenAI là paper Chinchilla của DeepMind năm 2022.
Điểm mấu chốt của Chinchilla là: nhiều model lớn thời đó thực ra undertrained — tức là quá nhiều parameters nhưng chưa được train trên đủ lượng tokens tương xứng. DeepMind cho thấy với một compute budget cố định, cách phân bổ tốt hơn không phải lúc nào cũng là làm model thật lớn; thay vào đó, cần cân bằng tốt hơn giữa model size và training tokens. Cụ thể, paper này kết luận rằng trong huấn luyện compute-optimal, khi model size tăng gấp đôi thì số training tokens cũng nên tăng gấp đôi. Model Chinchilla 70B, được train trên khoảng 1.3 nghìn tỷ tokens với cùng ngân sách compute như Gopher 280B, lại vượt Gopher và nhiều model lớn khác trên nhiều benchmark. [4]
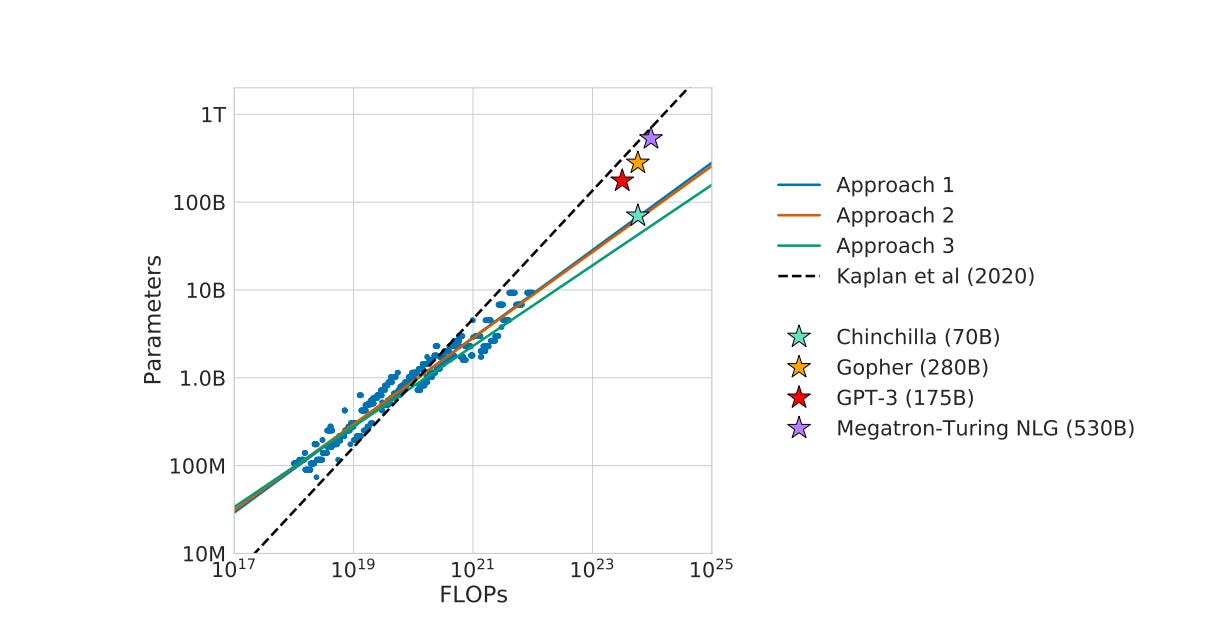
Hình này minh họa mối quan hệ giữa lượng tính toán (FLOPs) và kích thước mô hình (số tham số) trong các mô hình AI.
Giải thích đơn giản mô hình trên:
FLOPs là lượng tính toán dùng để huấn luyện (càng sang phải càng nhiều tài nguyên)
Parameters là số lượng tham số của mô hình (càng lên cao thì mô hình càng lớn)
Các mô hình cũ (GPT-3, Gopher, Megatron) nằm gần đường nét đứt và Chinchilla nằm thấp hơn → ít tham số hơn nhưng hiệu quả hơn
Đây là một bước ngoặt rất lớn về tư duy.
Trước Chinchilla, nhiều người nhìn scaling theo hướng “bigger is better”. Sau Chinchilla, ngành bắt đầu chuyển sang câu hỏi tốt hơn: compute của mình nên được phân bổ như thế nào để đạt hiệu quả tối ưu? Nói cách khác, scaling law không còn chỉ là “scale nhiều hơn”, mà là scale đúng cách. [5]
4. Vấn đề của cách hiểu cũ: scale không phải cứ phình to là đủ
Đây là chỗ nhiều người mới tìm hiểu AI hay nhầm.
Scaling law không có nghĩa là chỉ cần tăng parameters mãi mãi. Nếu hiểu như vậy, ta sẽ bỏ sót ít nhất ba điều.
Thứ nhất, lợi ích từ scale thường đi theo kiểu diminishing returns. Model vẫn tốt lên, nhưng không phải tăng 10 lần tài nguyên là được 10 lần chất lượng. Ý nghĩa của power law là sự cải thiện có thể dự đoán được, chứ không phải tăng tuyến tính vô hạn.
Thứ hai, data quality và cách phân bổ compute trở nên ngày càng quan trọng. Chinchilla cho thấy không thể chỉ nhồi thêm parameters mà bỏ quên lượng dữ liệu train.
Thứ ba, khi base model đã rất mạnh, phần còn lại của cuộc chơi không nằm trọn trong pre-training nữa. Từ đây, ngành AI bắt đầu mở sang những lớp scaling mới.
5. Từ một scaling law sang nhiều lớp scaling
Đây là điểm mình thấy thú vị nhất khi nhìn lại bức hình đã phân tích trước đó.
Nếu dùng ngôn ngữ hiện đại hơn, ta có thể hình dung sự tiến hóa của AI như một chuỗi:
Chat GPT thường → reasoning model → AI agent → AI system
Đó không phải là taxonomy học thuật cố định của toàn ngành, nhưng nó là một cách diễn giải rất hữu ích để hiểu điều gì đang xảy ra. NVIDIA hiện mô tả bức tranh scaling hiện đại qua ba lớp chính là pretraining scaling, post-training scaling và test-time scaling; đến năm 2026, trong các công bố hạ tầng mới, hãng này còn đẩy mạnh thêm khái niệm agentic inference / agentic AI như một mặt trận scaling tiếp theo. [3]
Điều quan trọng là:
intelligence ngày nay không còn chỉ đến từ việc train model lớn hơn, mà đến từ nhiều lớp compute được áp dụng ở những thời điểm khác nhau của vòng đời model.
6. Lớp thứ hai: post-training scaling
Sau khi có một pre-trained model mạnh, câu hỏi tiếp theo là: làm sao biến nó thành thứ thực sự hữu dụng?
Ở đây xuất hiện post-training scaling. Theo mô tả của NVIDIA, lớp này bao gồm các kỹ thuật như fine-tuning, distillation, reinforcement learning, pruning, quantization và synthetic data augmentation. Mục tiêu không chỉ là làm model “thông minh hơn”, mà còn làm nó phù hợp hơn với nhiệm vụ, rẻ hơn khi triển khai, và dễ dùng hơn trong sản phẩm thực tế. NVIDIA thậm chí lập luận rằng việc tạo cả một hệ sinh thái derivative models có thể tiêu tốn lượng compute lớn hơn rất nhiều so với pretraining model gốc. [3]
Nếu pre-training giống như cho model đi học phổ thông và đại học, thì post-training là giai đoạn dạy nó làm một nghề cụ thể.
Một legal model, một coding model, một medical assistant, hay một enterprise copilot thường không được xây chỉ bằng “pretrain xong là đủ”. Chúng được định hình qua nhiều lớp post-training để phù hợp hơn với domain, hành vi người dùng và ràng buộc sản phẩm. [3]
Trong hình mà mình đã phân tích trước đó, cụm “fine-tune pre-trained models” và “quantize to NVFP4” nằm ở lớp này. Chỗ đó nên được hiểu như sau: scaling không chỉ là tăng sức mạnh lý thuyết, mà còn là tối ưu để model chạy được ngoài đời thực. NVIDIA mô tả NVFP4 là một định dạng floating-point 4-bit được giới thiệu cùng kiến trúc Blackwell nhằm tăng hiệu quả training và inference ở độ chính xác thấp hơn nhưng vẫn giữ chất lượng đủ tốt cho nhiều workload. [6] [7]
Mình có để một số bài viết mình research để viết bài này, các bạn có thể vào để đọc chi tiết nếu quan tâm sâu hơn nhé.
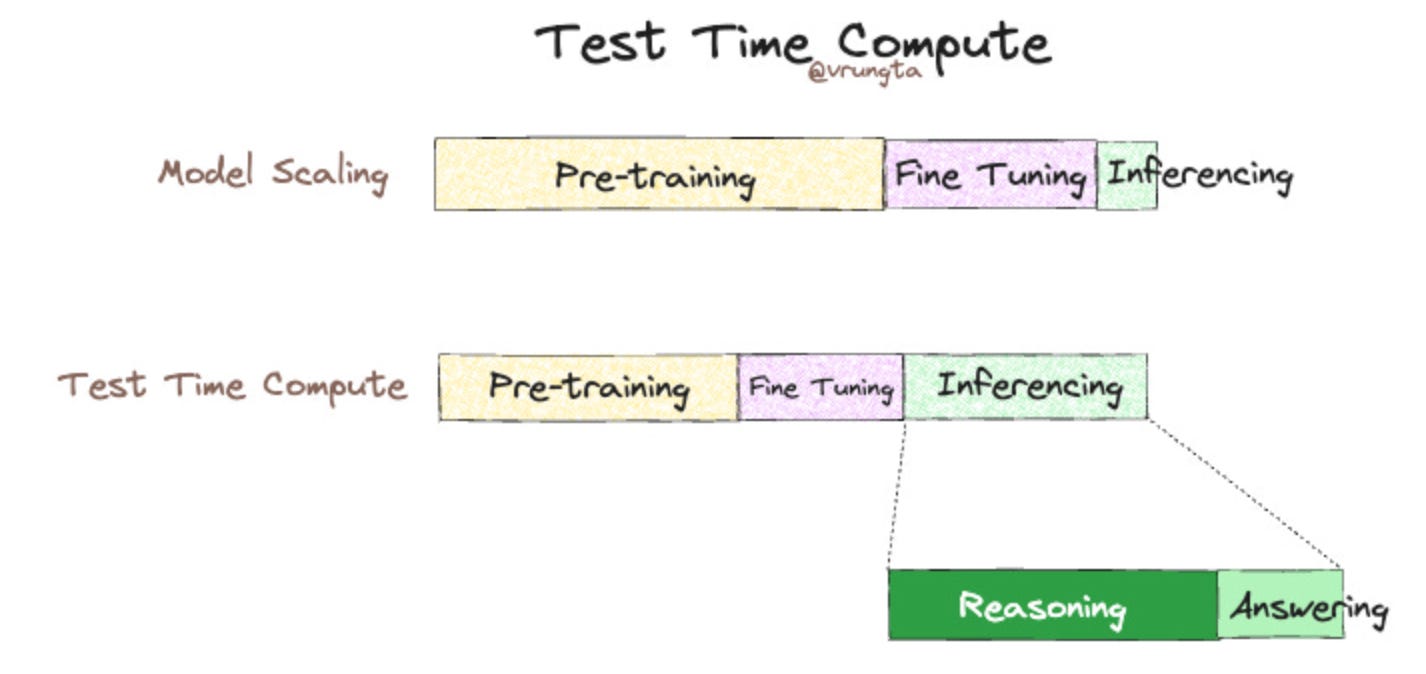
7. Lớp thứ ba: test-time scaling, hay “long thinking”
Đây là một trong những thay đổi lớn nhất của AI giai đoạn gần đây.
Trước đây, khi nói scale, người ta chủ yếu nghĩ đến lúc train. Nhưng với reasoning models, scale còn xảy ra ở thời điểm model đang trả lời. OpenAI mô tả rõ điều này trong bài viết về o1: hiệu năng của model cải thiện ổn định khi tăng train-time compute qua reinforcement learning, và cũng cải thiện khi cho model thêm thời gian suy nghĩ ở test time [8].
Đây chính là thứ nhiều người gọi là test-time scaling hay “long thinking”.
Nghĩ đơn giản: cùng một model, nếu cho nó thêm compute ở lúc inference, model có thể thử nhiều hướng giải hơn, tự kiểm tra sai sót, chia bài toán thành nhiều bước và chọn hướng tốt hơn trước khi trả lời. OpenAI mô tả o1 học cách tinh chỉnh chain of thought, nhận ra lỗi, sửa lỗi và đổi chiến lược khi hướng hiện tại không hiệu quả [8].
Đó là lý do vì sao ngày nay, một model “không lớn hơn quá nhiều” vẫn có thể cho cảm giác thông minh hơn rõ rệt nếu nó được phép suy nghĩ lâu hơn và được thiết kế tốt cho reasoning.
Trong hình ban đầu, nhánh “test-time scaling” được nối với các từ khóa như MoE, NVL72 và Dynamo. Phần này nói về hạ tầng. NVIDIA mô tả GB200 NVL72 là rack-scale system phục vụ các mô hình rất lớn, đặc biệt có lợi cho inference của trillion-parameter LLMs và MoE; còn Dynamo là inference framework mã nguồn mở để phục vụ generative AI ở môi trường phân tán với mục tiêu giảm latency và scale inference hiệu quả hơn. Nói ngắn gọn: nếu muốn “long thinking” thực sự chạy được ở quy mô lớn, bạn không chỉ cần model tốt, bạn cần cả một lớp serving stack cực mạnh phía sau [9].
8. Lớp thứ tư: agentic scaling
Đây là chỗ bức hình trở nên rất đáng suy nghĩ.
Tầng trên cùng của hình mô tả Agentic Scaling bằng một cụm rất trực diện:
“AI talking to AI.”
Cần nói rõ một nuance quan trọng: nếu Kaplan scaling laws và Chinchilla là những mốc nghiên cứu rất nền tảng, thì agentic scaling hiện vẫn thiên về một cách diễn giải mới của industry hơn là một “định luật” đã được chuẩn hóa như trong sách giáo khoa. Cụm này được NVIDIA nhấn mạnh trong các thông điệp hạ tầng 2025–2026, đặc biệt khi nói đến thời điểm agentic AI bắt đầu đòi hỏi low-latency, large-context inference ở quy mô cực lớn [3].
Nhưng dù tên gọi có còn đang được định hình, trực giác đằng sau nó là rất mạnh.
Khi AI chuyển từ trả lời một câu hỏi sang việc thực hiện workflow nhiều bước, dùng tool, gọi API, đọc tài liệu, tự kiểm tra, phản biện kết quả, thậm chí phối hợp giữa nhiều agent với nhau, thì “intelligence” không còn nằm gọn trong một model đơn lẻ nữa. Nó nằm ở cả hệ thống.
Và khi đó, bài toán scale đổi bản chất không chỉ là model accuracy mà là
orchestration
context management
memory
retry
verification
latency
cost per task
throughput khi nhiều agent cùng chạy
NVIDIA nói khá rõ điều này trong công bố về Vera Rubin: agentic workloads tạo ra nhu cầu rất cao về low-latency và large-context inference, còn reinforcement learning và agentic AI cũng đòi hỏi nhiều môi trường CPU để test và validate kết quả model tạo ra [10].
Đây là lý do mình cho rằng nếu trước kia lợi thế cạnh tranh của AI nằm nhiều ở “ai train được model to hơn”, thì tương lai gần lợi thế sẽ nằm ngày càng nhiều ở câu hỏi: ai biến model thành hệ thống làm việc tốt hơn.
Và rõ ràng Claude đang cho thấy họ thực sự đang chứng minh được điều này, mình có bài viết trên Threads đạt 65k views nói về góc nhìn cách Anthropic thực hiện 74 releases trong vòng 52 ngày [11].
9. Nhìn lại bức hình: vì sao nó hữu ích?
Thứ hay của bức hình mình phân tích trước đó không nằm ở chỗ nó định nghĩa học thuật hoàn hảo, mà ở chỗ nó giúp ta nhìn thấy một chuyển dịch rất thật của ngành AI:
Pre-training scaling: tăng sức mạnh nền của model
Post-training scaling: tinh chỉnh để model usable hơn
Test-time scaling: cho model thêm compute để suy nghĩ tốt hơn khi trả lời
Agentic scaling: để nhiều model, tool và workflow phối hợp thành một hệ thống giải quyết công việc
Nói cách khác, intelligence không chỉ được nạp vào lúc train nữa. Nó còn được mở rộng lúc deploy, lúc inference, và lúc orchestration ở cấp system. Phần mình vẽ lại theo hướng GPT thường → reasoning model → AI agent → AI system thực chất là cách diễn đạt lại đúng tinh thần đó. Nó không phủ định scaling law truyền thống; nó cho thấy scaling law đang đi lên thêm nhiều tầng mới.
10. Điều mình rút ra
Nếu bạn làm product hoặc build AI application, đây có lẽ là insight quan trọng nhất:
không nên nhìn AI chỉ qua benchmark của base model.
Một sản phẩm AI mạnh ngày nay có thể thắng không phải vì họ có model lớn nhất, mà vì họ:
post-train tốt hơn
cho model reasoning đúng lúc
tổ chức workflow agent thông minh hơn
quản lý context tốt hơn
tối ưu latency và cost tốt hơn
xây được vòng verify/retry đáng tin cậy hơn
Tức là lợi thế cạnh tranh đang dịch chuyển từ model-centric sang system-centric.
Điều này cũng giải thích vì sao nhiều sản phẩm dùng các model khá giống nhau nhưng trải nghiệm thực tế lại khác xa nhau. Cái khác không chỉ nằm ở “bộ não”, mà nằm ở toàn bộ cấu trúc vận hành xung quanh bộ não đó.
Lời Kết
Nếu phải tóm gọn trong một câu, mình sẽ nói thế này:
Scaling Law bắt đầu như quy luật cho thấy model mạnh lên khi tăng parameters, data và compute; nhưng trong kỷ nguyên AI hiện nay, “scale” đã trở thành một kiến trúc nhiều lớp — từ pre-training, post-training, test-time reasoning cho đến agentic systems.
Và có lẽ đó mới là cách hiểu đúng hơn về AI ở thời điểm này.
Không phải chỉ là model to hơn.
Mà là compute được đặt đúng chỗ hơn.
Không phải chỉ là train mạnh hơn.
Mà là cả hệ thống biết suy nghĩ, phối hợp và thực thi tốt hơn.
Lâu rồi mình mới viết một bài mà nó hơi học thuật và chuyên sâu thế này, ý tưởng bài viết đến từ Podcast mới của Jensen Huang, mình đã tổng hợp và kết nối nhiều mảng lại với nhau, rồi cố gắng viết sao vừa cho đúng bản chất vừa đủ dễ hiểu.
Và mình nghĩ, càng đi sâu vào AI, mình càng nhận ra:
thứ quan trọng không còn chỉ là model mạnh bao nhiêu, mà là ta hiểu nó đang scale theo lớp nào, dùng compute ở đâu, và biến intelligence đó thành giá trị thực như thế nào.
Đó cũng là lý do mình muốn viết bài này để không chỉ nhìn AI như một chuỗi release mới mỗi tuần, mà nhìn nó như một hệ thống đang được xây lên từng lớp một.
Nếu bạn đọc tới đây, cảm ơn bạn rất nhiều.
Hy vọng bài viết này giúp bạn có một khung nhìn rõ hơn về Scaling Law, và cũng mở ra thêm một góc nhìn mới về cách AI đang phát triển hôm nay.