
Memory trong Claude Code
LLM là stateless và mọi memory là illusion được tạo ra bởi hệ thống bao quanh model. Hiểu cơ chế, phân loại và cách quản lý memory hiệu quả để Claude Code hoạt động đáng tin cậy.

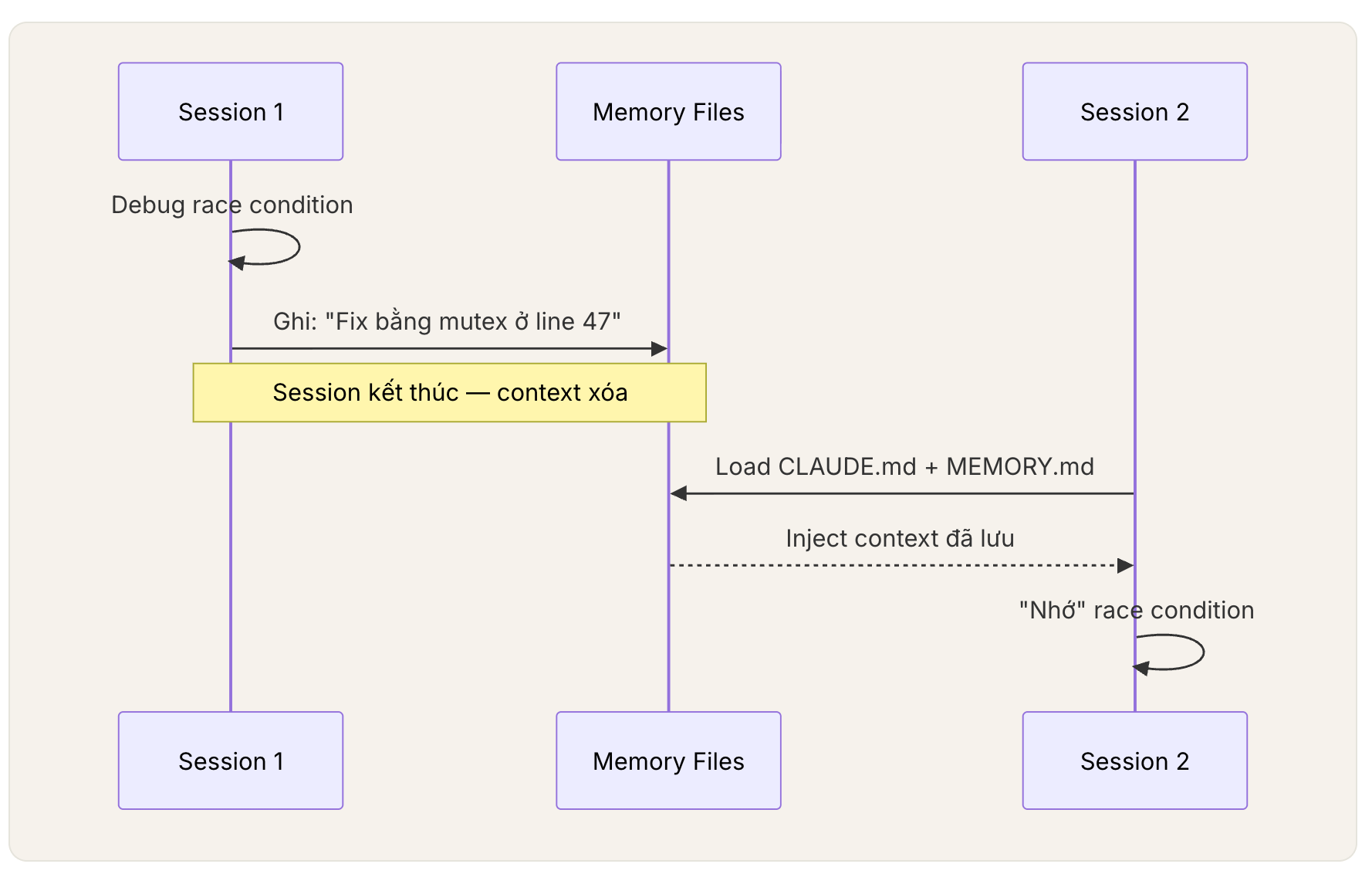
Có một trải nghiệm khá quen thuộc khi làm việc với Claude Code.
Bạn mở một session mới, bắt đầu giải thích cho Claude về project: architecture đang dùng, command nào chạy được, file nào không nên sửa, module nào đang có bug, quyết định kỹ thuật nào đã chốt với team. Sau một lúc, Claude bắt đầu hiểu dần. Nó suggest đúng hơn, ít đi sai hướng hơn, và đôi khi còn phản hồi như một teammate đã quen với codebase.
Nhưng hôm sau, bạn mở session mới.
Claude lại hỏi lại những điều cũ.
Nó không nhớ command hôm qua đã chạy fail. Nó không nhớ bug hôm qua vừa debug xong. Nó không nhớ bạn đã dặn “đừng refactor phần này vì đang phụ thuộc vào team khác”. Cảm giác lúc đó rất dễ khiến mình nghĩ: “AI này sao hay quên vậy?”
Nhưng thực ra, vấn đề không phải Claude lười nhớ. Vấn đề nằm ở bản chất của LLM.
LLM không có trí nhớ dài hạn tự nhiên như con người. Mỗi lần model được gọi, nó nhận vào context, xử lý, rồi trả ra output. Những gì nó “biết” tại thời điểm đó chủ yếu là những gì đang nằm trong context window. Khi session kết thúc, nếu không có cơ chế lưu lại và nạp lại thông tin, gần như mọi thứ biến mất.
Vì vậy, insight đầu tiên cần hiểu là:
Memory trong Claude Code không phải là thứ model tự có. Memory là thứ ta xây xung quanh model.
Nói cách khác, Claude không thật sự “nhớ”. Nó chỉ đọc lại những gì bạn đã lưu và đưa vào context đúng lúc.
1. Memory là gì và tại sao cần nó?
Memory trong Claude Code nên được hiểu đơn giản là cơ chế giúp Claude có continuity giữa các session.
Hôm nay bạn làm việc với Claude, phát hiện một bug quan trọng, chốt một quyết định kỹ thuật, hoặc tìm được một command đúng để run test. Nếu những thông tin đó chỉ nằm trong đoạn chat hiện tại, session sau Claude có thể không biết gì về chúng.
Nhưng nếu bạn ghi chúng vào CLAUDE.md, memory folder, project note, hoặc một file rule nào đó, session sau Claude có thể đọc lại và tiếp tục từ nơi đã dừng.
Đây là điểm khác biệt rất lớn giữa hai cách dùng Claude Code.
Cách thứ nhất là dùng Claude như một chatbot coding. Mỗi lần mở lên là một lần giải thích lại. Cách thứ hai là dùng Claude như một agent có hệ thống memory. Mỗi session mới không bắt đầu từ con số 0, mà bắt đầu từ những gì project đã học được trước đó.
Memory không làm LLM hết stateless. Nó chỉ tạo ra cảm giác “nhớ” bằng cách lưu thông tin bên ngoài model và inject lại vào context.
Đây là lý do memory design quan trọng. Với project nhỏ, bạn có thể không cảm nhận rõ. Nhưng với project dài hạn, nhiều decision, nhiều bug history và nhiều convention nội bộ, memory tốt có thể quyết định Claude hữu ích hay gây nhiễu.
2. Có 4 loại memory cần phân biệt
Để dễ hiểu, hãy tưởng tượng Claude đang làm việc với bạn trong một project dài hạn. Có thứ nó cần nhớ trong vài phút, có thứ cần nhớ qua nhiều ngày, có thứ là bài học từ bug cũ, và có thứ là kiến thức nền đã nằm sẵn trong model. Bốn loại memory bên dưới tương ứng với bốn nhu cầu đó.
Khi nói đến memory, mình nghĩ không nên chỉ nghĩ đến một file ghi chú. Memory của AI agent nên được nhìn như một hệ thống nhiều tầng.
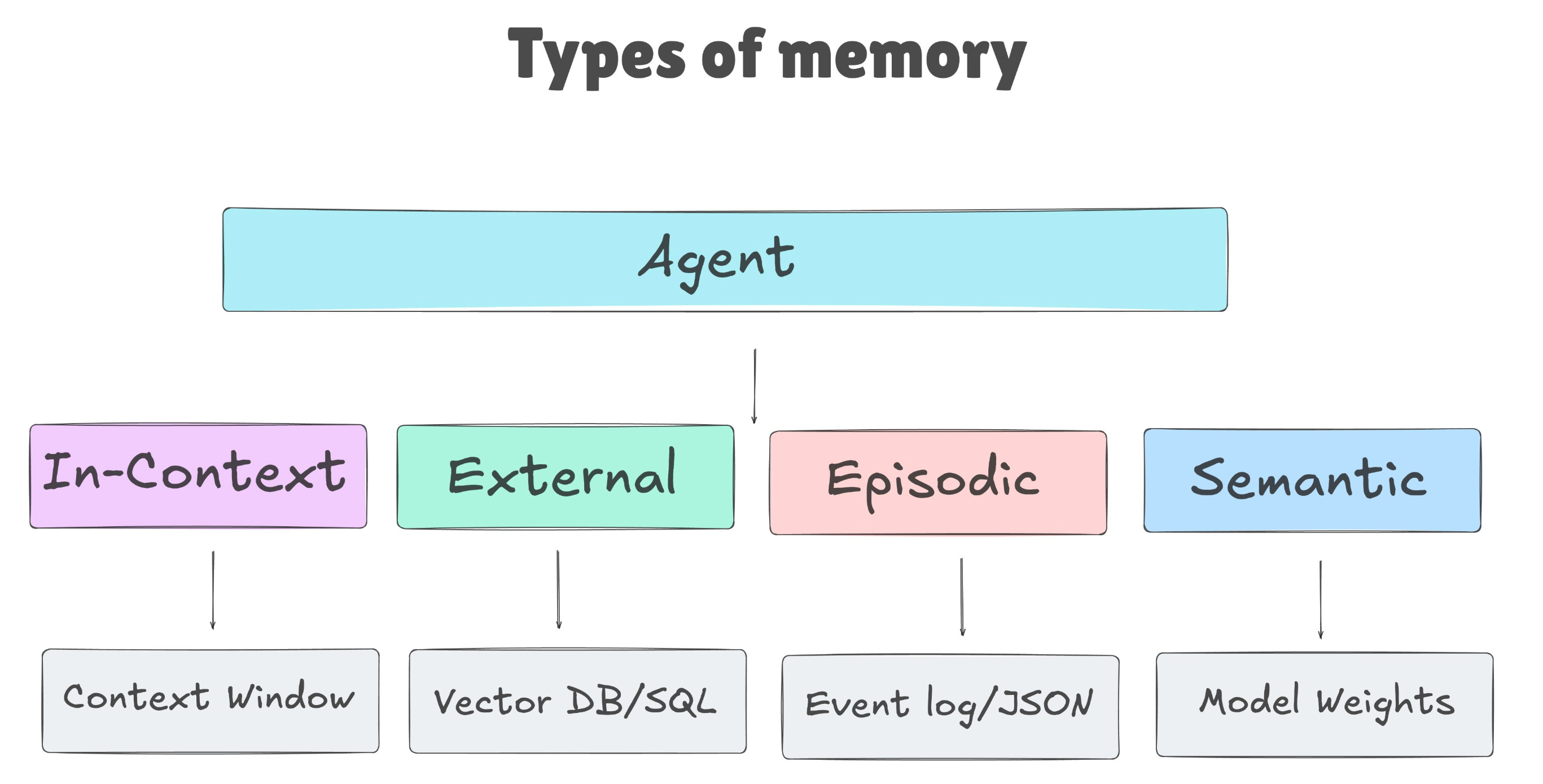
In Context Memory
Loại đầu tiên là In-Context Memory. Đây là những gì Claude đang thấy trong session hiện tại: prompt, instruction, file vừa đọc, history, tool output, nội dung CLAUDE.md được load vào. Nó giống như “bàn làm việc” trước mặt Claude. Thứ gì nằm trên bàn thì Claude dùng được ngay. Nhưng khi session kết thúc hoặc context bị compact, nhiều thứ sẽ biến mất. Nói đơn giản, đây là trí nhớ ngắn hạn của Claude trong một phiên làm việc.
Cấu trúc điển hình của context window:
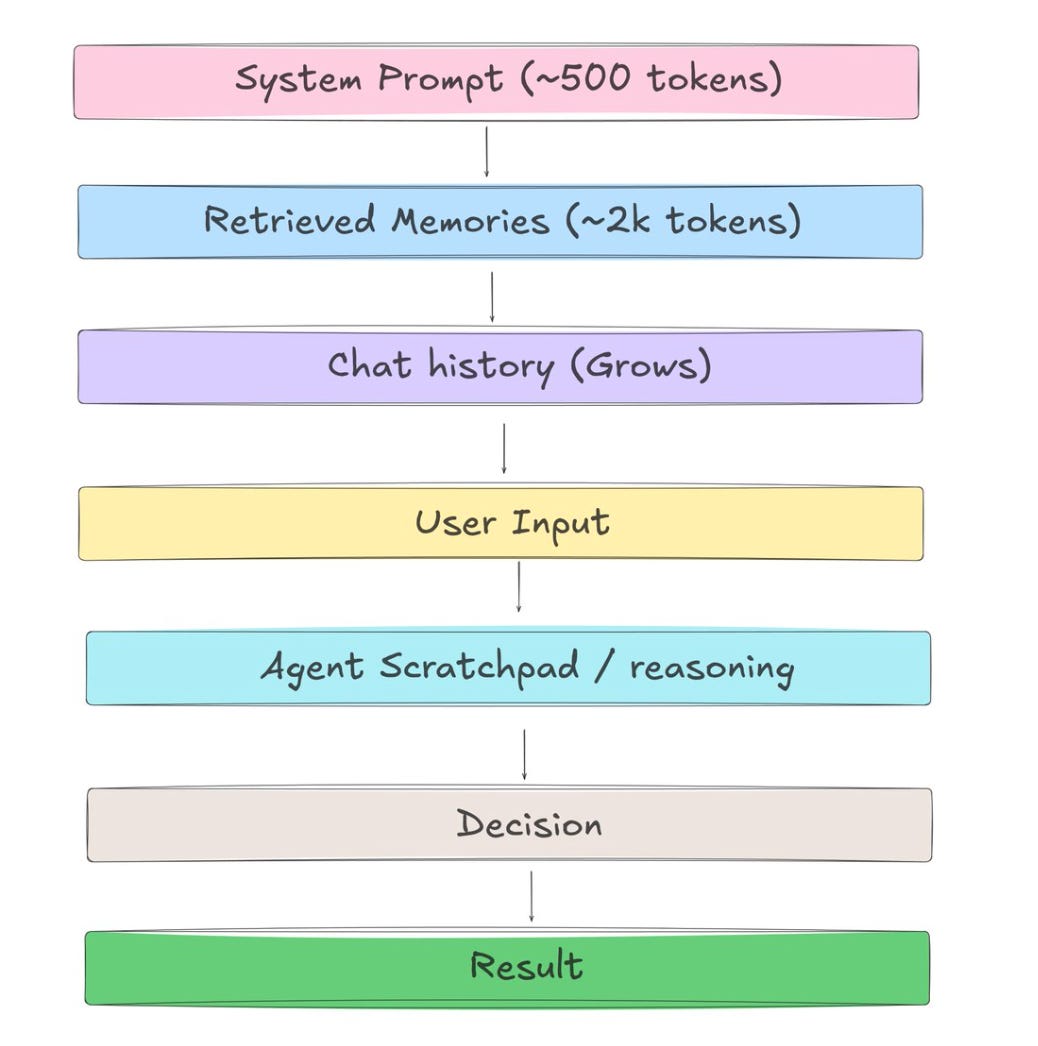
Khi history quá dài, Claude Code xử lý bằng 3 cách: Summarization (nén history cũ), Selective retention (giữ turns chứa facts/decisions quan trọng), hoặc Offload sang external memory. Compaction là lossy — những gì không được ghi ra file trước đó có thể mất vĩnh viễn.
External Memory
Loại thứ hai là External Memory. Đây là phần nằm ngoài model, ví dụ CLAUDE.md, markdown notes, database, wiki, vector store hoặc memory folder. Đây mới là thứ giúp Claude có continuity qua nhiều session. Trong Claude Code, dạng thực tế nhất thường là file-based memory. Nếu In-Context Memory là bàn làm việc, thì External Memory giống như sổ tay dự án.

Episodic Memory
Loại thứ ba là Episodic Memory. Đây là memory lưu lại các sự kiện đã xảy ra: bug đã debug, hướng đã thử, kết quả ra sao, bài học là gì. Ví dụ: “Duplicate reset password email từng xảy ra vì email được trigger ở cả service và background job.” Loại memory này rất giá trị vì nó giúp Claude học từ lịch sử thực chiến của chính project, không chỉ dựa vào kiến thức chung. Đây là phần giúp Claude không chỉ biết rule, mà còn biết project đã từng vấp ở đâu.
{
"task": "Debug duplicate reset password email",
"ruled_out": [
"Frontend double-click",
"Duplicate API call"
],
"hypothesis": "Backend may trigger email in both service and background job",
"outcome": "resolved",
"lesson": "When one action creates duplicate outputs, trace all downstream handlers"
}Semantic/ Parametric Memory
Loại cuối cùng là Parametric Memory. Đây là kiến thức nằm trong model weights: JavaScript là gì, REST API hoạt động thế nào, Redis dùng để làm gì, design pattern phổ biến ra sao. Loại này luôn có sẵn, nhưng không biết private codebase, decision nội bộ hay bug mới xảy ra của bạn.
Giới hạn của parametric memory
Parametric Memory là kiến thức Claude đã học sẵn trong quá trình training. Nó giúp Claude biết JavaScript, REST API, Redis hay design pattern là gì. Nhưng nó không biết project riêng của bạn vừa đổi từ Node.js 18 lên Node.js 22, không biết bug hôm qua đã fix, và không biết decision nội bộ của team. Vì vậy, kiến thức chung có thể dùng từ model, nhưng thông tin riêng của project phải nằm trong external memory.
Insight ở đây là:
Không phải thông tin nào cũng nên lưu cùng một chỗ. Rule của project, lịch sử debug, preference cá nhân và kiến thức nền tảng là bốn loại khác nhau. Nếu trộn hết vào một file, memory sẽ nhanh chóng thành rác.
3. Claude Code memory architecture: CLAUDE.md và Auto Memory
Trong Claude Code, có thể hiểu memory system gồm hai nhánh chính.
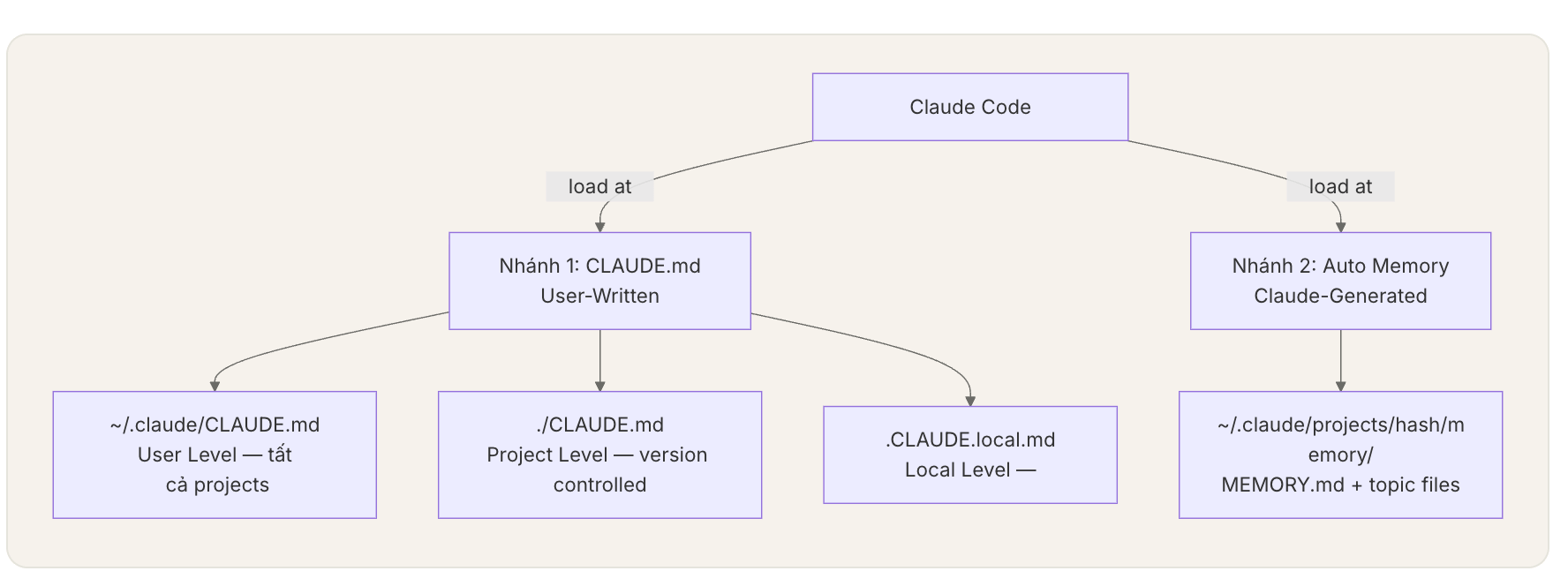
CLAUDE.md
Nhánh đầu tiên là CLAUDE.md — phần memory do người dùng viết. Đây là nơi bạn ghi lại các rule, convention, command, decision và gotcha quan trọng của project.
Nhưng CLAUDE.md không nên được xem là documentation. Mình thích xem nó là một behavioral contract (giống như 1 contract giữa bạn và Claude vậy)
Giới hạn thực tế: 80–120 lines. Trên ~150 instructions, khi số lượng instruction quá nhiều, Claude có thể không còn follow đều tất cả instruction, mà chỉ ưu tiên một phần nổi bật trong context.. Trên vài nghìn dòng (theo nghiên cứu khoảng 2000 line), CLAUDE.md có thể bắt đầu phản tác dụng vì Claude khó ưu tiên đúng thông tin quan trọng.
Mỗi dòng trong CLAUDE.md nên làm thay đổi cách Claude hành xử.
Ví dụ, dòng như sau không quá giá trị:
- Write clean code
- Follow best practices
- Use meaningful variable namesNhững câu này đúng, nhưng quá chung. Claude gần như đã mặc định biết.
Trong khi đó, những dòng như sau có giá trị hơn nhiều:
# AuthService — Backend API
## Build & Test
- Build: `./gradlew build`
- Test: `./gradlew test --tests "*.UnitTest"`
- Integration: `docker-compose up -d && ./gradlew integrationTest`
## Architecture - Do Not Change Without a Clear Reason
- Use the Repository pattern — do not query the database directly from services
- Use compensation transactions for cross-service failures (Sage pattern)
- All monetary values must use BigDecimal, never Double
## Active Gotchas
- TransactionService.processPayment() has a race condition at line 247
- UserRepository.findByEmail() case-sensitive — always lowercase the input first
- Migration 0023_add_mfa_table is still pending - DO NOT run it in production until approved
## Code Style
- Use async/await consistently; do not mix it with callbacks
- Add comments only when the WHY is not obvious
## Strictly Prohibited
- Do not use the any type in TypeScript — use unknown when the type is unclear
- Do not use direct console.log — use logger.info/error/debug
- Do not add retry logic — it is already handled at the infrastructure layerCác dòng này cụ thể, có ngữ cảnh, và giúp Claude tránh sai lầm thật.
Auto Memory
Nhánh thứ hai là Auto Memory phần Claude tự ghi lại sau quá trình làm việc. Nó có thể lưu command đã xác nhận chạy được, debugging insight, workflow preference hoặc các pattern Claude quan sát được.
Auto Memory hữu ích, nhưng không nên phó mặc hoàn toàn. Vì Claude có thể lưu thiếu, lưu thừa hoặc suy diễn sai. Với project quan trọng, mình vẫn tin rằng những decision quan trọng nên được con người chủ động ghi vào CLAUDE.md hoặc memory note rõ ràng.
MEMORY.md (index, 200 lines / 25KB) được auto-load mỗi session. Topic files được load on-demand theo relevance.
# Auto Memory — PaymentService (MEMORY.md)
## Build System
- `./gradlew build` works; `gradle build` fails (wrapper required)
- Integration tests cần `docker-compose up -d` trước, wait 10s
## Debugging History
- 2026-05-15: Race condition ở TransactionService:247 fix bằng synchronized block
- 2026-05-18: Null pointer ở PaymentMapper khi currency = null — add Optional wrapper
## User Preferences
- Viết test trước khi implement (TDD)
- Prefer small, focused commitsInsight ở phần này là:
CLAUDE.md không phải nơi lưu mọi thứ. Nó chỉ nên lưu những gì bạn muốn Claude luôn nhớ để hành xử đúng hơn trong tương lai.
4. Context Compaction: vì sao Claude có thể mất nuance
Một điểm dễ bị bỏ qua là Claude Code có context window giới hạn. Khi session quá dài, hệ thống phải compact tức là nén hoặc tóm tắt lại một phần context để tiếp tục làm việc.
Kích hoạt khi context đạt 75–92% capacity (~150K–184K token), hoặc trigger thủ công qua /compact.
Compaction là cần thiết, nhưng nó luôn có rủi ro: mất nuance.
Ví dụ ban đầu bạn nói:
“Tối ưu query performance cho bảng users, nhưng không được đổi schema vì team data đang phụ thuộc vào field cũ.”
Sau một lần summarize, nó có thể thành:
“User muốn tối ưu database performance.”
Ý chính vẫn còn, nhưng constraint quan trọng nhất - “không được đổi schema” - có thể đã biến mất.
Trong software development, mất một constraint nhỏ có thể dẫn đến một solution sai. Claude có thể suggest một hướng rất hợp lý về mặt kỹ thuật, nhưng lại phá vỡ một quyết định nội bộ, một dependency hoặc một business rule đã chốt.
Vì vậy, đừng xem conversation history là nơi lưu memory đáng tin cậy. Conversation giống như bảng trắng trong phòng họp. Nó hữu ích trong lúc làm việc, nhưng decision quan trọng phải được ghi vào biên bản.
Với Claude Code, “biên bản” đó chính là CLAUDE.md, memory note hoặc project wiki.
Một thói quen rất hữu ích là sau khi chốt một điều quan trọng, hãy nói:
Update CLAUDE.md with this decision so future sessions do not forget it.Insight ở đây rất đơn giản:
Thứ gì không được ghi ra ngoài context thì có thể mất sau compaction hoặc session mới.
5. Hooks: khi memory không chỉ là ghi chú, mà thành workflow
Nếu bạn mới bắt đầu dùng Claude Code, có thể bỏ qua hooks ở giai đoạn đầu. Đây là phần dành cho khi bạn đã có workflow lặp lại và muốn tự động hóa memory.
Nếu CLAUDE.md là bước đầu tiên, thì hooks là bước nâng cao hơn.
Hooks cho phép bạn chạy script tại một số thời điểm trong vòng đời của Claude Code: khi session bắt đầu, trước khi tool được dùng, sau khi tool chạy, hoặc khi session kết thúc.

Với memory, hooks rất mạnh vì chúng giúp tự động hóa hai việc: capture và restore.
Ví dụ, cuối mỗi session, một Stop hook có thể đọc transcript và extract các insight quan trọng: bug đã fix, command đã chạy thành công, decision mới, issue còn pending. Sau đó nó ghi lại vào MEMORY.md.
Hoặc trước khi Claude sửa file trong src/api, một hook có thể inject API rules. Khi Claude sửa migration, hook inject database rules. Nhờ vậy, Claude không cần load mọi rule trong mọi tình huống, mà chỉ nhận context đúng lúc cần.
Tuy nhiên, mình nghĩ không nên bắt đầu từ hooks ngay. Trước hết, hãy làm tốt file-based memory thủ công. Khi bạn thấy có workflow lặp lại, lúc đó mới automate bằng hooks.
Insight ở đây là:
Automation chỉ có giá trị khi workflow thủ công đã rõ. Nếu memory còn lộn xộn, hooks chỉ làm việc lộn xộn nhanh hơn.
6. Quản lý memory hiệu quả: curation quan trọng hơn accumulation
Một cái bẫy lớn khi nói về memory là nghĩ rằng càng lưu nhiều càng tốt.
Thực tế ngược lại: memory không được curate sẽ trở thành technical debt.
Ví dụ đơn giản hơn: 6 tháng trước project dùng Node.js 18, nên trong memory có rule “luôn dùng Node.js 18 để chạy project”. Sau đó team đã upgrade lên Node.js 22. Nếu rule cũ vẫn còn trong memory, Claude có thể tiếp tục hướng dẫn bạn cài Node.js 18, debug theo Node.js 18, hoặc suggest package version tương thích với Node.js 18.
Lúc này memory không còn giúp Claude làm việc tốt hơn. Nó đang kéo Claude quay lại một trạng thái cũ của project.
Đây là lý do memory cần được dọn dẹp như code. Rule nào còn đúng thì giữ. Rule nào outdated thì xóa. Bug nào đã resolved thì archive. Decision nào đã thay đổi thì update. Những instruction conflict nhau thì phải xử lý.
Một CLAUDE.md tốt nên ngắn, cụ thể và có tính hành động. Khoảng 80–120 dòng là hợp lý. Nếu dài hơn nhiều, nên tách ra thành nhiều file theo scope: API rules, database rules, frontend rules, debugging notes, architecture decisions.
Một cách chia tầng đơn giản:
Global memory: preference áp dụng mọi project.
Project memory: convention và decision của team.
Local memory: setup cá nhân, WIP notes, local environment.
Episodic memory: bug history, debugging lesson, decisions theo thời gian.
Insight quan trọng nhất:
Memory tốt không phải là lưu nhiều. Memory tốt là lưu đúng thứ, đúng chỗ, và xóa đúng lúc.
7. Ví dụ thực tế: debug một bug kéo dài nhiều ngày
Giả sử bạn đang debug một lỗi trong hệ thống gửi email.
Ngày đầu tiên, bạn phát hiện mỗi khi user bấm “Reset password”, hệ thống thỉnh thoảng gửi 2 email thay vì 1 email. Bạn kiểm tra phần giao diện trước, nhưng button không bị double-click. Bạn kiểm tra API log và thấy frontend chỉ gọi API một lần.
Đến cuối session, bạn chưa fix xong bug, nhưng đã loại trừ được một hướng quan trọng: lỗi không nằm ở frontend. Hypothesis mới là backend có thể đang trigger email ở hai nơi khác nhau: một lần trong ResetPasswordService, và một lần nữa trong background job hoặc event listener.
Nếu thông tin này không được lưu lại, ngày mai Claude có thể bắt đầu lại từ đầu. Nó có thể tiếp tục hỏi: “Có phải user double-click không?”, “Frontend có gọi API hai lần không?”, hoặc suggest bạn kiểm tra lại phần giao diện.
Nhưng nếu bạn ghi lại một note ngắn như sau, session sau Claude sẽ có điểm tựa để tiếp tục:
## Active Debug: Duplicate Reset Password Email
- Symptom: When a user clicks “Reset password”, the system sometimes sends 2 emails instead of 1.
- Ruled out: Frontend double-click issue. The button is not being clicked twice.
- Ruled out: Duplicate API call from frontend. API logs show the reset password endpoint is called only once.
- Current hypothesis: The backend may be triggering the email in two places: once inside ResetPasswordService, and once again from a background job or event listener.
- Next step: Trace the full reset password flow from API handler → service → event/job queue → email sender.
- Useful check: Search for all places calling sendResetPasswordEmail() or publishing a PasswordResetRequested event.Ngày hôm sau, Claude có thể đọc lại note này và tiếp tục đúng từ điểm đã dừng. Thay vì lặp lại những bước debug đã làm hôm qua, nó sẽ tập trung vào phần còn lại của flow: backend service, event listener, background job, hoặc email sender.
Khi bug được fix, bạn có thể update note thành:
## [RESOLVED] Duplicate Reset Password Email
- Root cause: The reset password email was triggered in two places: once inside ResetPasswordService, and once again from a background job.
- Fix: Keep the email trigger in ResetPasswordService only, and remove the duplicate trigger from the background job.
- Lesson: When one user action creates duplicate outputs, first verify whether the action is being triggered once or multiple times, then trace all downstream handlers that may react to the same event.Lần sau gặp một issue tương tự, Claude không chỉ dựa vào kiến thức chung. Nó có một episode thực tế từ chính project của bạn: lỗi từng xảy ra ở đâu, hướng nào đã loại trừ, root cause là gì, và bài học nào nên áp dụng lại.
Đây là giá trị của episodic memory.
Nó biến Claude từ một người chỉ trả lời từng câu hỏi riêng lẻ thành một cộng sự có khả năng tiếp nối lịch sử kỹ thuật của project.
8. Anti-patterns thường gặp
Anti-pattern đầu tiên là biến CLAUDE.md thành bãi rác. Mọi thứ đều được ném vào đó: changelog, todo, bug cũ, note cá nhân, decision đã deprecated. Sau vài tháng, file quá dài và Claude không còn follow tốt nữa.
Anti-pattern thứ hai là mong Claude nhớ từ session trước nhưng không ghi gì ra file. Bạn nói “project đã upgrade lên Node.js 22, đừng hướng dẫn theo Node.js 18 nữa”, Claude đồng ý. Nhưng nếu không lưu vào memory, session sau nó vẫn có thể suggest lại Node.js 18.
Anti-pattern thứ ba là giữ memory cũ quá lâu. Một rule từng đúng không có nghĩa là nó đúng mãi. Memory lỗi thời có thể gây hại nhiều hơn memory thiếu.
Anti-pattern thứ tư là lưu quá chung chung. Những câu như “write clean code” không giúp Claude hành xử khác đi. Memory tốt phải cụ thể, có context và có khả năng thay đổi decision của Claude.
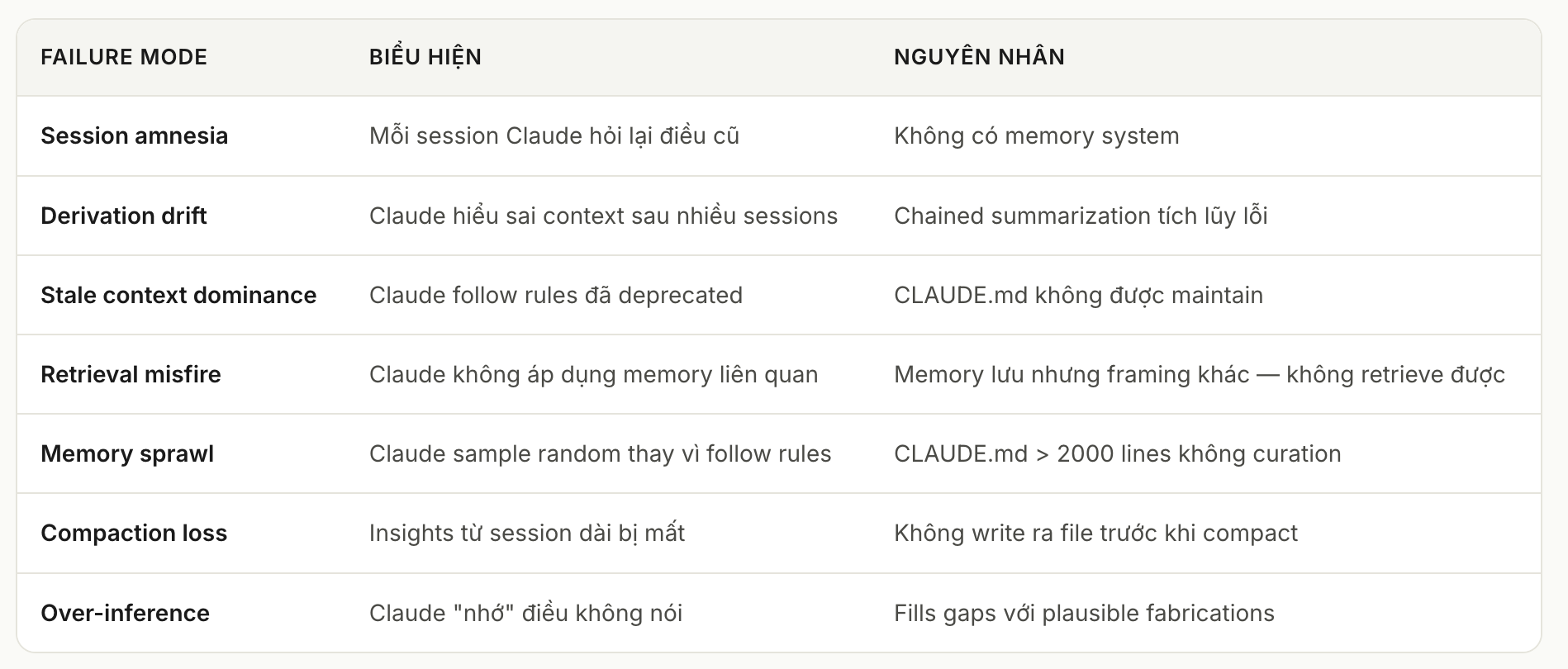
Insight ở đây là:
Memory không nên ghi lại những điều đúng chung chung. Memory nên ghi lại những điều nếu quên thì Claude sẽ làm sai.
9. Chiến lược nâng cao: own your memory
Một câu hỏi chiến lược hơn là: memory của AI agent nên thuộc về ai?
Nếu memory nằm hoàn toàn sau proprietary API, bạn khó biết nó đang lưu gì, khó chỉnh sửa, khó audit, khó version control, và khó mang sang tool khác. Với các thử nghiệm nhỏ, điều này có thể không quan trọng. Nhưng với project dài hạn, memory là tài sản kỹ thuật.
Nó chứa architecture decisions. Nó chứa debugging history. Nó chứa convention của team. Nó chứa lý do đằng sau những phần code nhìn có vẻ kỳ lạ. Nó chứa những bài học mà team đã trả giá để học được.
Vì vậy, mình thích file-based memory.
Markdown có thể đọc được, sửa được, commit được, review được, archive được và migrate được. Tool có thể thay đổi. Model có thể thay đổi. Nhưng memory của project nên nằm trong tay team.
Insight cuối cùng:
AI agent có thể là outsource. Nhưng memory của project nên là tài sản nội bộ.
Kết luận
Claude Code không thật sự nhớ như con người.
Nó không tự nhiên mang theo toàn bộ context của project qua nhiều session. Nhưng điều đó không làm nó kém hữu ích. Nó chỉ có nghĩa là ta cần thiết kế môi trường làm việc cho nó tốt hơn.
Thay vì mong Claude tự nhớ, hãy chủ động xây memory system.
Ghi lại những rule thật sự ảnh hưởng đến hành vi. Lưu những decision quan trọng trước khi session kết thúc. Biến debugging history thành episodic memory. Dọn dẹp memory cũ như refactor code. Và quan trọng nhất, hãy giữ quyền sở hữu memory của chính mình.
Vì trong dài hạn, AI coding agent mạnh không chỉ là agent có model tốt.
Nó là agent có context tốt. Memory tốt. Và khả năng tiếp tục công việc từ nơi hôm qua đã dừng lại.
Không có memory, mỗi session là một lần onboarding lại từ đầu. Có memory tốt, mỗi session là một bước tiếp theo trong cùng một hành trình.
Và có lẽ đây là thay đổi lớn nhất trong cách dùng AI coding agent: ta không chỉ học cách prompt tốt hơn, mà còn phải học cách thiết kế context tốt hơn.
Key Takeaways
LLM là Stateless; Memory là hệ thống bên ngoài model
CLAUDE.md là behavior contract, không phải documentation
Compaction là lossy, decision quan trọng phải ghi ra file
Memory không curate sẽ thành technical debt
Agent mạnh = model tốt + context tốt + memory tốt