
Loop Engineering
Bạn không còn prompt AI nữa, bạn đang viết cái vòng lặp để AI tự prompt thay bạn

Có một câu mình đọc gần đây và thấy nó chạm đúng vào cảm giác của mình khi quan sát làn sóng AI coding trong hơn một năm qua:
Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore. You should be designing loops that prompt your agents.
Câu nói này đến từ Peter Steinberger - cha đẻ của OpenClaw và hiện tại đang làm việc tại OpenAI.
Ý này nghe qua có vẻ giống một câu nói để gây chú ý. Nhưng càng nhìn vào cách các team kỹ thuật đang dùng Claude Code, Cursor, Devin-like agents, GitHub Copilot coding agent, hay các workflow tự động quanh CI/CD, mình càng thấy đây không còn là chuyện hype nữa.
Nó mô tả một sự dịch chuyển thật trong công việc của lập trình viên.
Trước đây, mình quen với hình ảnh một developer ngồi trước IDE, đọc requirement, viết code, chạy test, sửa bug, commit, mở PR. Khi AI coding assistant xuất hiện, vòng lặp đó chưa biến mất, chỉ là bên trong mỗi bước có thêm một người phụ việc. Developer prompt AI để viết một function, refactor một đoạn code, generate test, hoặc giải thích một lỗi build.
Nhưng bây giờ, tầng công việc lại dịch lên thêm một nấc.
Developer không chỉ prompt AI để viết code nữa. Developer bắt đầu viết ra những vòng lặp có khả năng tự prompt AI, tự đọc output, tự kiểm tra kết quả, tự quyết định có cần chạy tiếp hay không.
Nói cách khác, model không còn là “người bạn chat trong IDE”. Model trở thành một subroutine còn thứ quan trọng hơn là cái loop được xây quanh nó.
1. Prompt engineering không chết. Nó chỉ leo lên tầng cao hơn
Mỗi khi có một thuật ngữ mới xuất hiện, mình thường khá dè chừng. “Loop engineering” cũng vậy. Nghe nó rất dễ trở thành một từ mới để gọi lại những thứ cũ: automation, CI pipeline, agent workflow, cron job, script, orchestrator.
Nhưng sau khi bóc lớp từ ngữ ra, mình nghĩ điểm đáng chú ý nằm ở chỗ này: Prompt engineering không chết mà nó chỉ không còn nằm ở mức một câu prompt đơn lẻ nữa.
Trước đây, câu hỏi là:
“Mình nên viết prompt thế nào để AI làm đúng việc này?”
Bây giờ, câu hỏi bắt đầu trở thành:
“Mình nên thiết kế hệ thống thế nào để AI có thể tự đi qua nhiều vòng hành động, kiểm tra, sửa lỗi, và biết khi nào nên dừng?”
Đây là một thay đổi khá lớn.
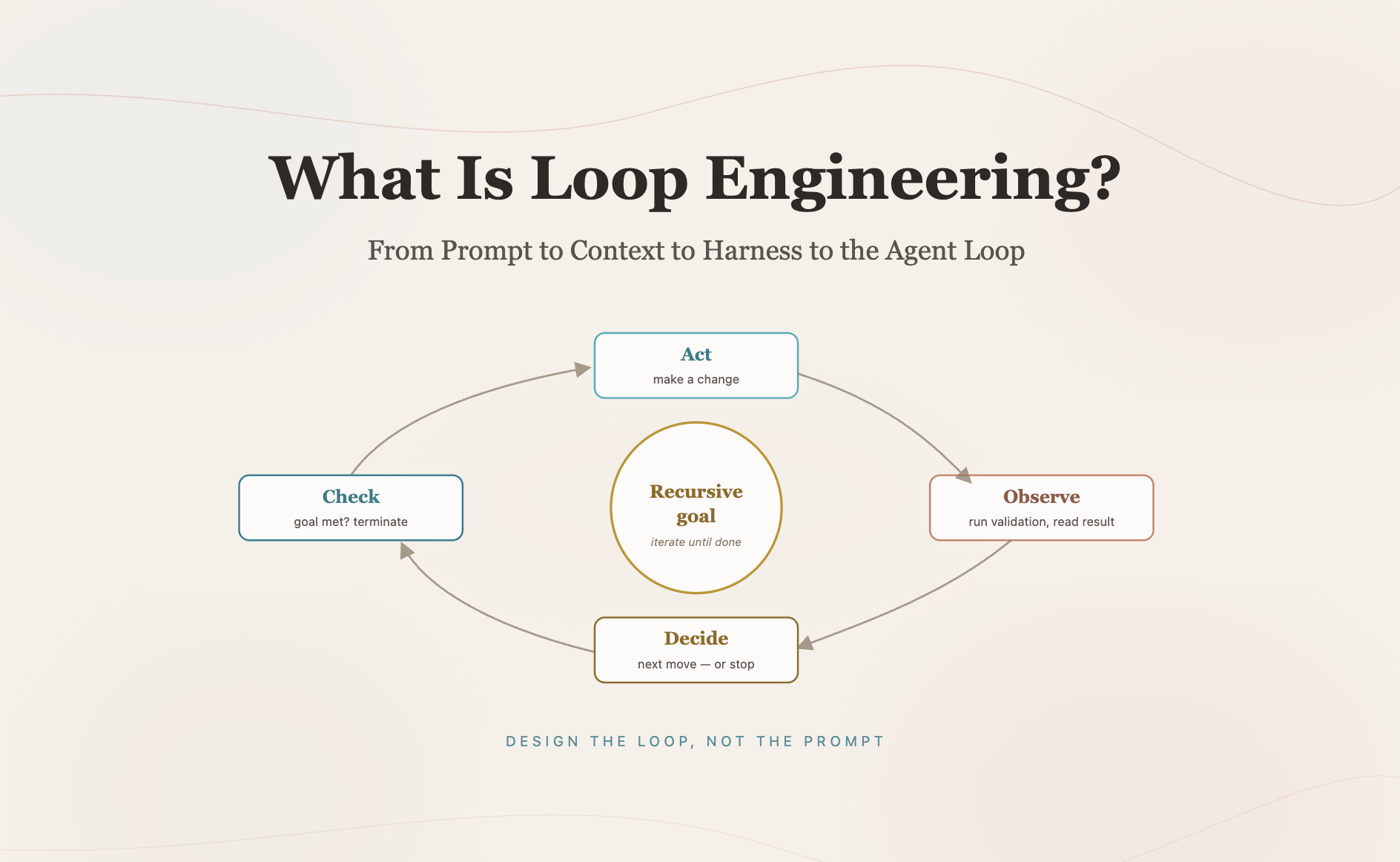
Vì khi bạn prompt một lần, bạn vẫn đang ngồi trong loop. Bạn nhìn kết quả, đánh giá đúng sai, rồi prompt tiếp. Trí tuệ thật sự của hệ thống vẫn nằm ở bạn. AI chỉ là một công cụ phản hồi theo từng lượt.
Nhưng khi bạn thiết kế một loop, bạn đang đưa một phần năng lực đánh giá và ra quyết định đó ra khỏi đầu mình, đặt nó vào một hệ thống có cấu trúc hơn: có trigger, có scope, có budget, có verifier, có stop condition, có state lưu bên ngoài cuộc hội thoại.
Lúc này, công việc của kỹ sư không đơn giản là “dùng AI tốt hơn”. Công việc trở thành “thiết kế một cơ chế để AI làm việc mà không phá hệ thống”.
2. Một loop thực ra là gì?
Nếu bỏ hết phần hào nhoáng, một loop chỉ là một chương trình nhỏ làm bốn việc.
Nó giao việc cho agent.
Nó đọc thứ agent tạo ra.
Nó kiểm tra xem việc đó đã xong chưa.
Nếu chưa, nó đưa lỗi hoặc bước tiếp theo ngược lại cho agent, rồi chạy tiếp.
Cấu trúc cơ bản luôn là:
mục tiêu → hành động → kiểm tra → phản hồi lỗi → lặp lại đến khi pass hoặc tự dừng.

Điểm khác biệt nằm ở chỗ: bạn không còn là người ngồi giữa từng vòng nữa.
Ví dụ đơn giản nhất là một PR babysitter.
Cứ mỗi 15 phút, loop kiểm tra các pull request đang mở có label agent-watch. Nếu CI đỏ vì một lỗi rõ ràng, nó cho agent thử fix một lần. Nếu main branch đã move, nó cho agent rebase một lần. Nếu CI xanh, nó dừng. Nếu vượt quá budget, ví dụ quá 5 phút, đụng quá 10 files, hoặc fix một lần vẫn fail thì nó dừng và ping người thật.
Nghe không quá viễn tưởng thậm chí khá tẻ nhạt. Nhưng chính những việc tẻ nhạt này mới là nơi loop có giá trị nhất.
Rất nhiều công việc engineering hằng ngày không khó vì bản thân nó phức tạp. Nó mệt vì nó lặp lại, nhiều ngữ cảnh nhỏ, và dễ bị bỏ sót. CI fail do cùng một lỗi dependency. Deploy xong cần gọi vài endpoint để chắc không regression. Comment từ nhiều channel cần gom lại theo theme. Một bug nhỏ cần sửa ở ba nơi, rồi chạy test để xác nhận.
Đó là loại việc một loop làm tốt hơn một prompt đơn lẻ.
3. Vì sao loop đang trở thành một tầng mới?
Mình nghĩ lý do không nằm ở chỗ model đột nhiên thông minh vượt bậc trong một đêm. Lý do là xung quanh model đã có đủ hạ tầng để biến nó thành một worker có thể vận hành trong hệ thống thật.
Ngày trước, muốn làm một loop nghiêm túc, bạn phải tự script gần như mọi thứ. Tự gọi model, tự parse output, tự chạy test, tự quản lý repo, tự giữ state, tự mở PR, tự báo kết quả về Slack.
Bây giờ, nhiều thứ đã trở thành built-in hoặc gần built-in trong coding tools.
Agent bây giờ không chỉ dừng ở việc gợi ý code. Nó có thể đọc repo, chạy command, sửa file, tạo branch, mở PR, đọc log lỗi, thậm chí chạy browser để verify UI. Nếu được nối thêm MCP hoặc các connector khác, nó còn có thể chạm vào issue tracker, database, docs, Slack, GitHub, tức là bắt đầu làm việc trong cùng một môi trường mà team kỹ thuật đang vận hành hằng ngày.
Khi những mảnh ghép này đủ nhiều, câu hỏi không còn là “AI có viết code được không?” nữa.
Câu hỏi trở thành: “Mình có thiết kế được một vòng lặp đủ an toàn để giao việc cho nó không?”
Đây là chỗ vai trò của engineer dịch lên một tầng mới.
Thay vì trực tiếp viết từng dòng code, bạn viết ra môi trường, luật chơi, giới hạn, tiêu chí hoàn thành, và cơ chế kiểm tra để một agent có thể viết code bên trong đó.
Nó khá giống việc từ một người tự làm mọi task chuyển sang làm người thiết kế process cho một team nhỏ. Chỉ khác là team nhỏ này chạy bằng model, API, test suite, Git worktree, CI pipeline, và một đống stop condition.
4. Một loop không bắt đầu từ một prompt mà từ cấu trúc
Một sai lầm mình thấy khá dễ xảy ra là nghĩ loop chỉ là “prompt lặp lại nhiều lần”.
Không phải.
Một loop có cấu trúc cần ít nhất vài bộ phận rất rõ.

Đầu tiên là trigger. Loop phải biết khi nào nó được khởi động: theo lịch, theo webhook, theo file change, theo một label rơi vào PR, hoặc theo một event trong CI. Nếu bạn vẫn là người bấm chạy mỗi lần, đó chưa hẳn là loop; đó chỉ là manual workflow được lặp lại bằng tay.
Thứ hai là isolation. Khi nhiều agent chạy song song, mỗi agent cần một không gian riêng, thường là một checkout hoặc git worktree riêng. Nếu không, hai agent có thể sửa cùng một file, ghi đè lẫn nhau, hoặc tạo ra một trạng thái repo rất khó debug.
Thứ ba là context được viết xuống. Đây là điểm mình thấy rất quan trọng. Agent không nên đoán convention của dự án từ đầu mỗi lần chạy. Project rules, build steps, coding conventions, constraint về folder, naming, test command, kiến trúc hệ thống nên được viết trong những file như AGENTS.md, VISION.md, hoặc tài liệu tương tự mà agent đọc lại mỗi run.
Thứ tư là khả năng chạm vào tool thật. Nếu agent chỉ in ra “đây là patch bạn nên apply”, bạn vẫn là người bê phần còn lại. Một loop mạnh phải có khả năng mở PR, link ticket, chạy test, đọc CI, post kết quả, hoặc cập nhật board.
Thứ năm là verifier độc lập. Đây có lẽ là phần dễ bị xem nhẹ nhất. Agent viết code không nên là người duy nhất quyết định code đó đã ổn. Một model tự review bài của mình thường rất dễ dãi. Nó có xu hướng giải thích vì sao output của nó hợp lý, thay vì tìm cách chứng minh output đó sai. Vì vậy, loop nghiêm túc cần một checker khác: test suite, linter, build, SAST, browser automation, hoặc một sub-agent độc lập không bị nhiễm reasoning của agent tạo ra code.
Cuối cùng là state phải sống ở bên ngoài cuộc hội thoại. Model có thể quên, context window có thể đầy, những bản tóm tắt qua nhiều vòng lặp cũng dần làm mất chi tiết. Nhưng một file markdown, một queue, một issue board hay một database thì không gặp vấn đề đó. Nếu loop được thiết kế để chạy nhiều lần, nó cần một nơi lưu lại những gì đã hoàn thành, những gì còn dang dở, vì sao lần trước thất bại và cần tránh điều gì ở lần chạy tiếp theo.
Nhìn như vậy, loop engineering thật ra không phải là một kỹ năng “prompting” thuần túy. Nó nằm giữa software engineering, automation, QA, DevOps, system design, và một chút product thinking.
5./goal và sự thay đổi trong cách giao việc cho agent
Một ví dụ khá dễ hình dung là /goal trong Claude Code.
Thay vì nói với agent: “Sửa giúp tôi test auth đang fail”, bạn đặt một end state có thể kiểm chứng hơn:
“Làm đến khi tất cả tests trong test/auth pass. Không thay đổi public API. Không sửa migration. Dừng sau 20 lượt nếu chưa giải quyết được.”
Thực ra, đó không còn là một prompt nữa. Nó giống một bản mô tả kết quả cần đạt kèm theo các ràng buộc và tiêu chí kiểm chứng.
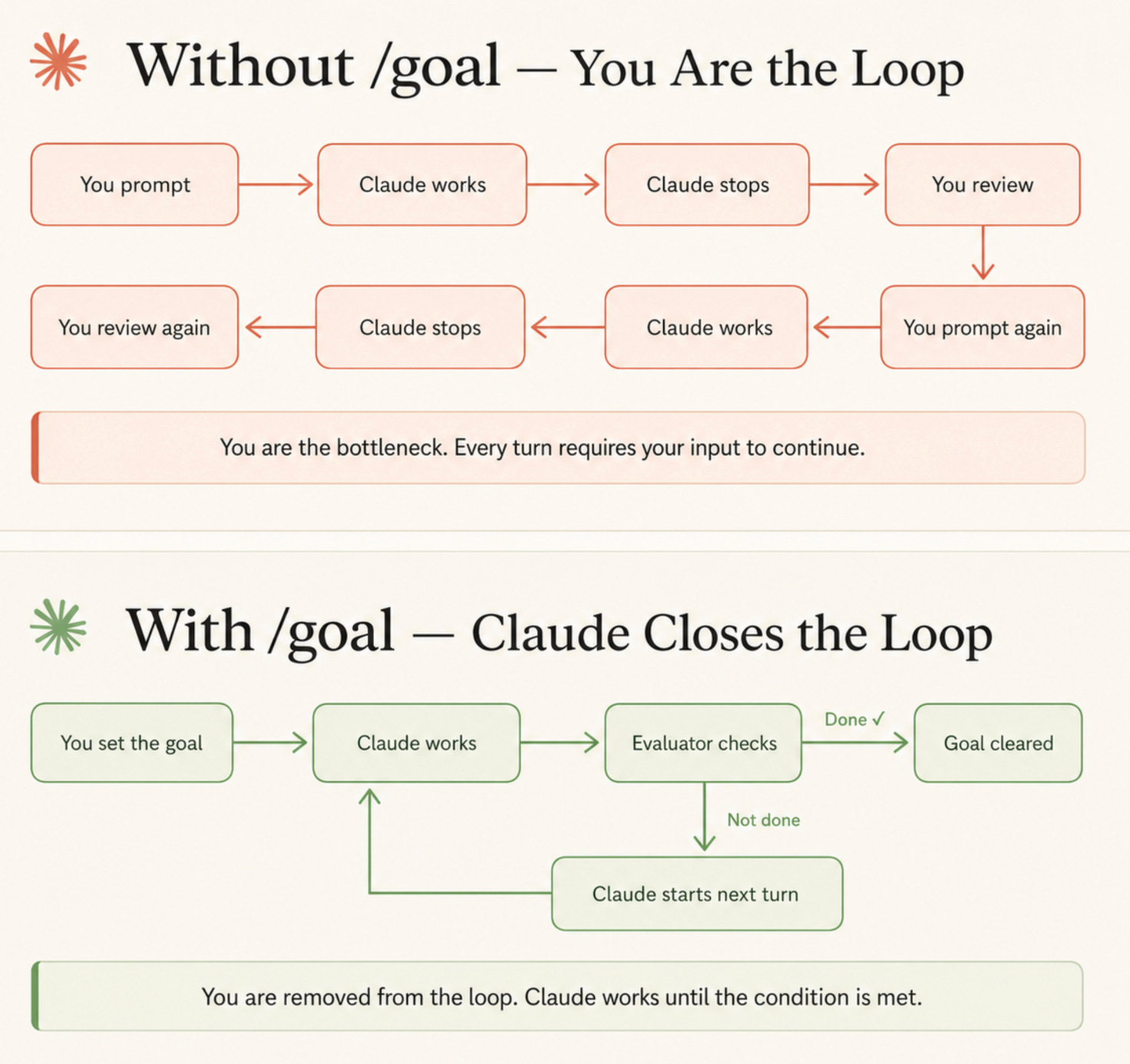
Nó có bốn phần:
Một là end state — trạng thái cuối cùng mình muốn đạt.
Hai là evidence — bằng chứng nào chứng minh đã đạt.
Ba là constraints — agent không được phá những ranh giới nào trên đường đi.
Bốn là budget — agent được tiêu tối đa bao nhiêu lượt, bao nhiêu file, bao nhiêu thời gian, bao nhiêu tiền.
Điều này nghe nhỏ, nhưng nó thay đổi cách mình nghĩ về việc giao việc cho AI.
Nếu prompt mơ hồ, model sẽ tự lấp khoảng trống bằng cách có lợi nhất cho transcript. Nó có thể dừng sớm. Nó có thể đổi định nghĩa “done”. Nó có thể sửa test thay vì sửa bug. Nó có thể đi vòng qua lỗi thay vì xử lý nguyên nhân gốc. Nó có thể tạo ra một câu trả lời trông rất hợp lý, trong khi hệ thống thật vẫn hỏng.
Vì vậy, một goal tốt không nên giống một lời nhờ vả. Nó nên giống một acceptance criteria.
Mình nghĩ đây là nơi kinh nghiệm làm PM/BA/Tech Lead bắt đầu có lợi thế. Người quen viết requirement tốt, biết tách scope, biết định nghĩa done, biết đặt constraint, biết nghĩ đến edge case, sẽ giao việc cho agent tốt hơn rất nhiều so với người chỉ viết một câu prompt chung chung.
6. Chi phí thật không còn nằm ở token, mà nằm ở số vòng lặp
Trong hai năm qua, khi nói về chi phí AI, mọi người thường hỏi model nào rẻ hơn, context bao nhiêu token, input/output cost thế nào.
Những câu hỏi đó vẫn quan trọng. Nhưng trong loop engineering, mình nghĩ chúng không còn là tầng tối ưu chính nữa.
Chi phí thật nằm ở số lần loop phải chạy trước khi hội tụ.
Một model rẻ hơn nhưng cần sáu vòng để sửa xong một task có thể đắt hơn một model mạnh hơn làm đúng trong hai vòng. Một verifier yếu khiến loop tưởng đã xong khi chưa xong thì chi phí không chỉ là token. Nó là bug lọt vào codebase. Một stop condition lỏng khiến loop retry vô hạn thì chi phí không chỉ là tiền API. Nó là rủi ro vận hành.
Vì vậy, metric nên chuyển từ “cost per call” sang “cost per finished task”.
Mình thấy đây là một điểm rất đáng suy nghĩ. Trong môi trường production, chúng ta vốn không tối ưu từng dòng code riêng lẻ. Chúng ta tối ưu throughput, lead time, defect rate, rollback rate, cycle time. Với AI loop cũng vậy. Một vòng gọi model không có ý nghĩa nếu nó không tiến gần hơn đến một task hoàn thành thật.
Nói cách khác, ngày xưa bạn tune prompt. Bây giờ bạn tune loop.
Bạn tune cách nó fail.
Bạn tune cách nó dừng.
Bạn tune cách nó tự kiểm tra.
Bạn tune cách nó giữ memory.
Bạn tune cách nó escalate cho người thật.
Và những thứ đó mới là nơi chi phí thực sự của một loop.
7. Loop càng tốt, rủi ro comprehension debt càng lớn
Có một failure mode mình thấy rất đáng sợ: loop chạy càng tốt, team càng dễ ship nhanh code mà không ai thật sự hiểu.
Nếu agent tạo ra vài dòng code, bạn review được. Nếu agent tạo ra một PR nhỏ, bạn vẫn có thể đọc. Nhưng nếu nhiều loop chạy liên tục, tự sửa CI, tự refactor, tự tạo PR, tự update docs, tự xử lý backlog nhỏ, codebase có thể thay đổi nhanh hơn tốc độ hiểu của team.
Lúc đó, vấn đề không phải là “AI viết code sai”.
Vấn đề là repo bắt đầu chứa nhiều quyết định kỹ thuật mà không ai trong team thật sự đã suy nghĩ qua.
Đây là một loại nợ mới: comprehension debt.
Khoảng cách giữa “hệ thống đang chứa gì” và “team hiểu gì về hệ thống” ngày càng rộng. Và khoản nợ này thường không lộ ra khi mọi thứ đang chạy ổn. Nó chỉ lộ ra vào ngày có incident, ngày cần debug một bug production kỳ lạ, hoặc ngày cần thay đổi một phần kiến trúc mà không ai biết tại sao nó được viết như vậy.
Điều trớ trêu là failure mode này mạnh hơn khi loop tốt lên, không phải khi loop tệ đi.
Một loop tệ fail sớm, bạn phải nhìn vào. Một loop tốt tạo cảm giác yên tâm, nên bạn ít nhìn hơn. Và chính lúc đó, hệ thống âm thầm đi xa khỏi hiểu biết của con người.
Đó cũng là lý do mình nghĩ loop engineering không làm review biến mất, mà chỉ thay đổi đối tượng được review. Trước đây chúng ta đọc code để tìm lỗi. Còn khi agent bắt đầu tạo ra phần lớn thay đổi, thứ cần được xem xét nhiều hơn lại là các quyết định kỹ thuật phía sau. Những thứ như change log, architecture note hay PR summary vì thế trở nên quan trọng hơn trước. Và ở một thời điểm nào đó, câu hỏi giá trị nhất có lẽ không còn là “test pass chưa?”, mà là “chúng ta có còn hiểu và đồng ý với hướng mà hệ thống đang được xây dựng không?”.
8. Verifier yếu là con bug đắt nhất
Nếu phải chọn một phần quan trọng nhất trong loop, mình sẽ chọn verifier.
Không phải model. Không phải prompt. Không phải context length.
Mà là verifier.
Vì verifier là thứ quyết định loop có được phép dừng hay không.
Nếu verifier quá yếu, loop sẽ bắt đầu tối ưu cho việc "trông như đã xong" thay vì thực sự hoàn thành công việc. Mọi dashboard đều xanh, PR vẫn được mở, agent vẫn báo done, nhưng bên dưới lớp tín hiệu tích cực đó, lỗi và nợ kỹ thuật có thể đang âm thầm tích tụ mà không ai nhận ra.
Một verifier tốt nên có khả năng nói “không”.
Test pass hoặc fail. Build compile hoặc không. Linter zero hoặc non-zero. Endpoint trả đúng response hoặc không. Browser automation nhìn thấy đúng state hoặc không. Secret scanning có phát hiện credential hay không.
Còn một verifier chỉ “đánh giá xem có ổn không” bằng cảm giác của cùng model vừa viết code thì rất nguy hiểm. Nó giống để học sinh tự chấm bài văn của mình bằng tiêu chí “em thấy cũng ổn”.
Mình không phủ nhận vai trò của những đánh giá mang tính chủ quan. Nhiều quyết định về UI, UX, nội dung hay kiến trúc vẫn cần đến kinh nghiệm và trực giác của con người. Nhưng với một loop chạy không người trông, trực giác là chưa đủ. Nó cần những tiêu chí khách quan có thể xác nhận hoặc bác bỏ kết quả một cách rõ ràng.
Bởi nếu không có khả năng chứng minh mình sai, hệ thống sẽ luôn tìm cách chứng minh mình đúng..
9. Security tax: càng tự động, càng phải thu hẹp quyền
Một loop chạy lúc bạn ngủ cũng có thể gây lỗi lúc bạn ngủ.
Điểm này nghe hiển nhiên, nhưng rất dễ bị đánh giá thấp khi chúng ta phấn khích với agentic workflow.
Một coding agent có quyền sửa file, chạy command, mở PR, đọc logs, dùng credentials, gọi tools, truy cập repo, đọc issue tracker về bản chất là một attack surface mới. Nếu nó bị prompt injection qua issue description, qua comment, qua dependency script, qua file docs, hoặc qua một “skill” nào đó, rủi ro không còn nằm trong chat window nữa. Nó chạm vào hệ thống thật.
Vì vậy, loop càng mạnh thì permission càng phải hẹp.
Agent càng mạnh thì quyền hạn càng phải được giới hạn rõ ràng. Một agent không nên có khả năng làm nhiều hơn phạm vi của task, cũng như secrets không nên xuất hiện trong logs chỉ vì tiện cho việc debug. Những lớp bảo vệ như secret scanning, dependency audit, SAST hay permission review cần trở thành một phần của loop, thay vì được để lại cho bước kiểm tra thủ công sau cùng.
Mình nghĩ đây là một cái bẫy rất phổ biến. Khi agent liên tục cho kết quả tốt, chúng ta có xu hướng nới lỏng dần các giới hạn để mọi thứ vận hành trơn tru hơn. Nhưng trong engineering, sự thuận tiện thường đi trước rủi ro một bước. Đến khi nhìn thấy rủi ro, khoản nợ đó thường đã được tích lũy từ rất lâu.
10. Khi nào không nên dùng loop?
Không phải task nào cũng đáng loop.
Loop hiệu quả khi task lặp lại, scope rõ, và có cách tương đối rẻ để biết khi nào nó xong. Nếu thiếu một trong ba điều này, loop có thể chỉ tự động hóa sự mơ hồ.
Một thay đổi one-shot làm một lần là xong thì không cần loop. Dựng loop cho nó chỉ là overhead.
Một việc còn quá khám phá như “tìm hiểu vì sao user rời bỏ” cũng không nên loop ngay. Việc đó chưa có pass condition. Nó cần thinking, research, interview, framing, hypothesis. Nếu ép vào loop quá sớm, agent sẽ tự tạo ra cảm giác tiến độ bằng những output dài nhưng chưa chắc có giá trị.
Một việc không có verifier rẻ cũng nên cẩn thận. Nếu cách duy nhất để biết đúng sai là mắt bạn, thì bạn vẫn đang ở bên trong loop. Lúc đó, tốt hơn là dựng verifier trước, rồi mới nghĩ đến automation.
Mình thích cách nghĩ này: đừng loop task chỉ vì có thể. Hãy loop task vì nó có hình dạng phù hợp để tự động hóa an toàn.
11. Vậy engineer nên học gì tiếp theo?
Nếu nhìn từ xa, có thể nhiều người sẽ kết luận rằng AI agent làm developer bớt quan trọng đi nhưng mình lại thấy ngược lại.
Nó làm vai trò engineer quan trọng hơn, nhưng ở tầng khác.
Kỹ sư không chỉ cần biết viết code. Kỹ sư cần biết thiết kế hệ thống tạo ra code. Điều đó đòi hỏi nhiều năng lực rất “cũ”: hiểu architecture, hiểu test, hiểu CI/CD, hiểu security, hiểu requirement, biết chia nhỏ scope, biết định nghĩa done, biết review trade-off, biết kiểm soát blast radius, biết khi nào nên tự động hóa và khi nào nên giữ con người trong vòng lặp.
AI không làm những kỹ năng đó biến mất. Nó làm chúng lộ ra rõ hơn.
Một người chỉ biết prompt cho ra code sẽ nhanh chóng bị giới hạn bởi chất lượng output từng lần. Nhưng một người biết thiết kế loop tốt có thể biến agent thành một worker tương đối đáng tin trong một phạm vi cụ thể.
Từ đó, leverage khác hẳn.
Không phải leverage kiểu “tôi gõ nhanh hơn”.
Mà là leverage kiểu “tôi thiết kế được một hệ thống chạy qua nhiều vòng mà vẫn biết dừng, biết kiểm tra, biết nhớ, biết fail an toàn”.
Đây là một năng lực engineering rất thật.
12. Điều mình rút ra
Mình không nghĩ tương lai của lập trình viên là ngồi ngủ trong khi agent tự ship toàn bộ sản phẩm. Cách nghĩ đó vừa hấp dẫn vừa nguy hiểm.
Mình nghĩ tương lai gần thực tế hơn là: developer sẽ dành ít thời gian hơn cho những vòng lặp cơ học, và nhiều thời gian hơn để thiết kế, giám sát, kiểm tra, và chịu trách nhiệm cho những vòng lặp đó.
Câu hỏi “model nào tốt nhất?” vẫn còn giá trị, nhưng ngày càng kém trung tâm.
Câu hỏi quan trọng hơn là:
Loop của bạn có biết khi nào nó xong không?
Nó có verifier đủ mạnh không?
Nó có giới hạn quyền không?
Nó có budget không?
Nó có nhớ state bên ngoài context window không?
Nó fail theo cách an toàn hay fail âm thầm?
Và cuối cùng: team của bạn có còn hiểu hệ thống mà loop đang thay đổi mỗi ngày không?
Đó mới là phần khó.
Vì cái đắt nhất không phải là model.
Cái dễ hỏng nhất cũng không phải là prompt.
Cái đắt và dễ hỏng nhất là cái vòng lặp bạn xây quanh nó.
Nên nếu phải tóm lại bằng một câu, mình sẽ nói thế này:
Đừng chỉ học cách prompt AI để viết code. Hãy học cách thiết kế một loop đủ chặt để AI có thể làm việc, tự kiểm tra, biết dừng, và khi sai thì sai trong phạm vi bạn kiểm soát được.
Đó có lẽ là một trong những kỹ năng quan trọng nhất của software engineering trong vài năm tới.