
LLM Knowledge Base
Xây Dựng Second Brain Với AI & Obsidian: Khi LLM Tự Động Viết Wiki Cho Bạn

Hầu hết các hệ thống Personal Knowledge Management (PKM) đều chết theo cùng một cách: Bạn lưu ngày càng nhiều — nhưng hiểu ngày càng ít.
Càng đọc nhiều bài viết, paper, tutorial… bạn càng mất thời gian để tóm tắt, tagging, và kết nối chúng.
Cuối cùng, hệ thống trở thành một “data graveyard” — không phải Second Brain. Nhưng điều gì xảy ra nếu bạn không cần viết note nữa?
Gần đây, Andrej Karpathy đã tweet về một workflow mang tính cách mạng, đạt hơn 45M views chỉ sau 2-3 ngày.

Đây không còn là note-taking nữa. Đây là một hệ thống Knowledge Compilation — nơi dữ liệu thô được “biên dịch” thành tri thức có cấu trúc.
AI Agent tự động đọc, tóm tắt, tạo liên kết và xây dựng toàn bộ hệ thống Wiki. LLM writes the wiki, you curate. (LLM viết, bạn quản trị).
Tuy nhiên, từ một idea trên X đến một hệ thống thực chiến là một khoảng cách rất xa. Mình khá thích workflow này và từ đó mình quyết định tự tay architecture và code một hệ thống Open-Source dựa đúng trên triết lý đó, sử dụng Claude Code (hoặc Cursor/Windsurf) đóng vai trò làm Backend Engine, và Obsidian làm UI/Frontend.
Dự án hiện đã public trên GitHub: LLM Knowledge Base.
Dưới đây là chi tiết những gì mình làm.
1. Bức Tranh Toàn Cảnh (System Overview)
Để bạn dễ hình dung, đây là toàn cảnh workflow của hệ thống. Nó hoạt động như một vòng lặp khép kín gồm 4 bước như hình bên dưới.
Bạn có thể hiểu toàn bộ hệ thống như một pipeline:
Raw Data → LLM Compile → Knowledge Graph → Query → Feedback Loop
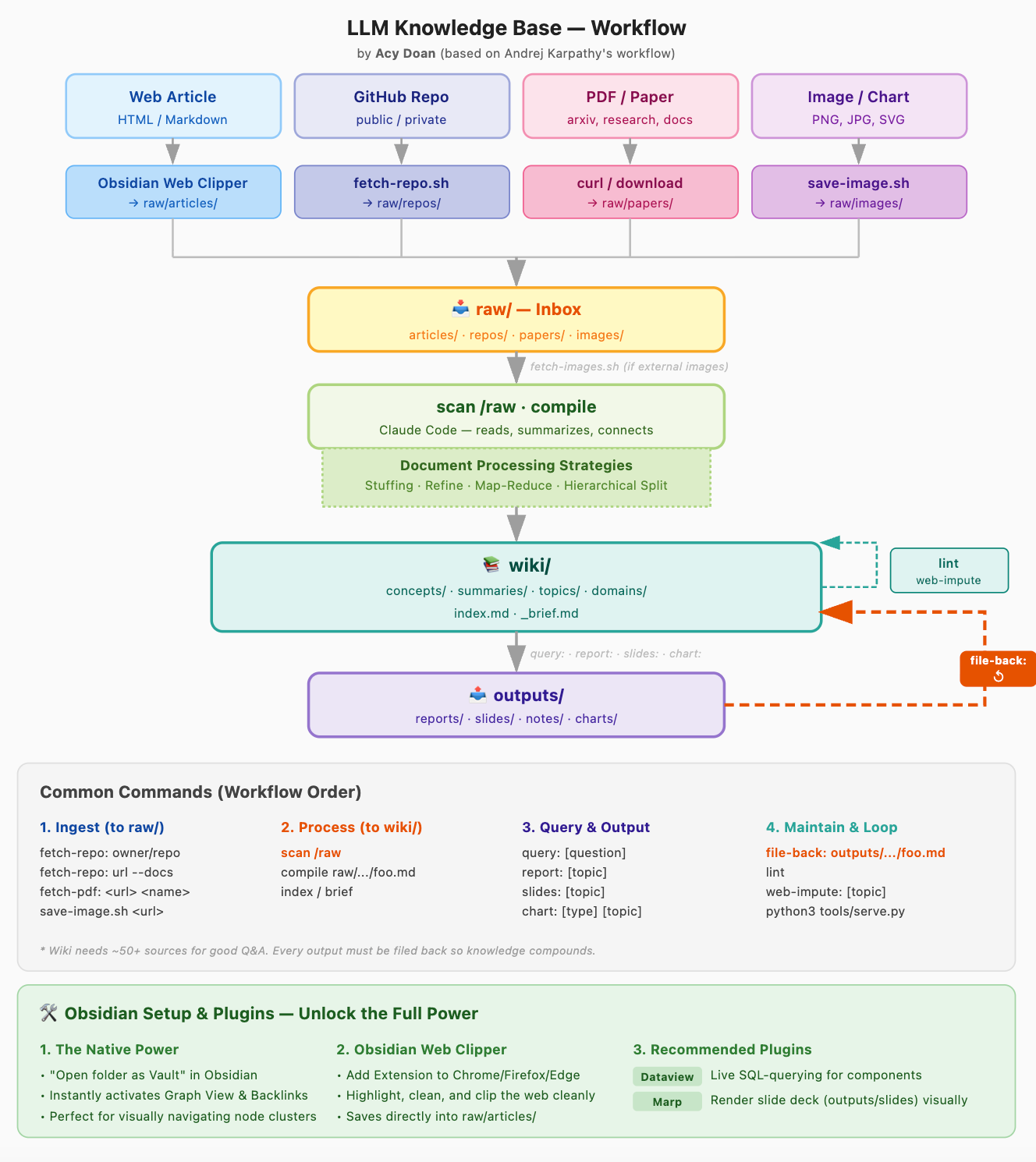
Các bước chi tiết như sau:
Ingest (Nạp Dữ Liệu): Nhận mọi loại dữ liệu thô (bài báo web, PDF học thuật, hay thậm chí cả một repo GitHub) vào thư mục
raw/.Compile (Biên Dịch): LLM đọc dữ liệu thô, chiết xuất các khái niệm (concepts), viết bài tóm tắt và tự động gán các liên kết
[[wikilink]]để hình thành Đồ thị Tri thức (Knowledge Graph).Query & Output (Hỏi Đáp & Trích Xuất): Bạn đặt câu hỏi phức tạp. AI quét mớ bòng bong Wiki và xuất ra các Báo cáo, Slide thuyết trình (Marp format), hoặc Vẽ biểu đồ.
File-back (Lai Tạo): Đây là vòng lặp hồi tiếp. Các Insight sinh ra từ bước 3 bị ép phải ghi ngược trở lại vào hệ thống (bước 2) để kiến thức tự sinh sôi.
2. Hướng Dẫn Kích Hoạt Nhanh (User Guide)
Hệ thống được thiết kế theo dạng Plug-and-play. Nếu bạn muốn tự tay thử nghiệm ngay workflow này, dưới đây là luồng trải nghiệm 2 phút:
Bước 1: Clone repos này về máy Bật Terminal và clone dự án về máy:
git clone https://github.com/hoadoan1997/llm-knowledge-base.git
cd llm-knowledge-baseBước 2: Load raw data
Lưu các bài báo yêu thích (dạng .md), đưa file PDF, hoặc dẫn link GitHub repo vào các thư mục tương ứng trong folder raw/.
Hãy cài Extension Obsidian Web Clipper trên Chrome/Firefox để lưu bài viết trên web với đúng định dạng chuẩn nhất.
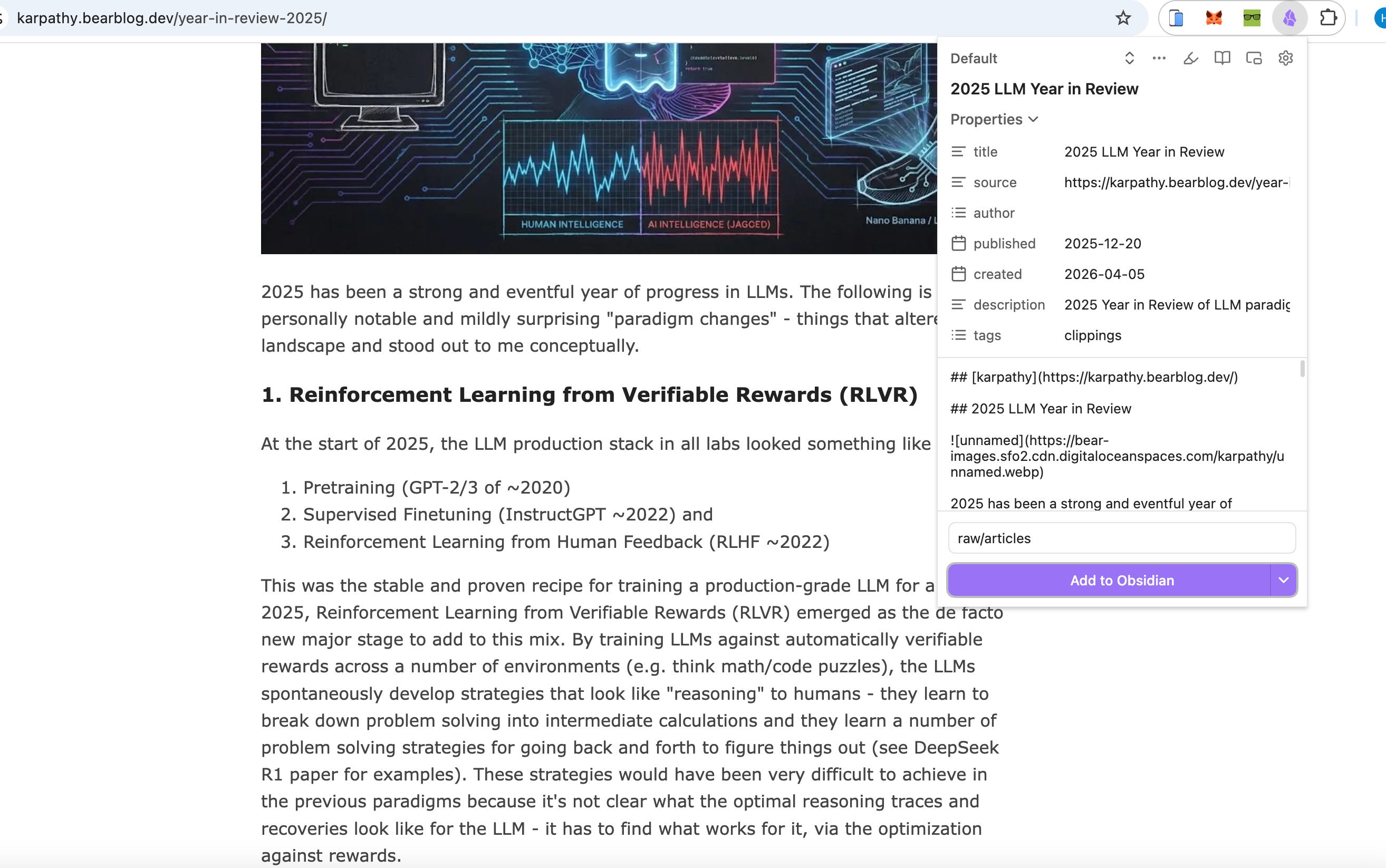
Sau khi Add về Obsidian thì sẽ hiển thị như thế này.
Bước 3: Sử dụng Agent để Scan các file
Mở thư mục dự án bằng Claude Code (Dùng Claude Code Chat hoặc Terminal đều được), Cursor, hoặc Windsurf.
Hệ thống Agent sẽ tự động add CLAUDE.md và AGENTS.md vào bộ nhớ. Bạn khởi chạy bằng 1 trong các lệnh chat sau:
Lệnh quan trọng nhất của repo này sẽ là: scan /raw,khi gõ lệnh này thì hệ thống sẽ thực hiện các bước sau:
1. Scan — Chạy scan.sh --new để phát hiện file chưa compile.
2. Kiểm tra độ dài — Chạy scan.sh --info để xác định strategy.
3. Fetch images — Phát hiện các external URL trong file, chạy fetch-images.sh để tải ảnh về raw/images/ và rewrite URL thành local path.
4. Đọc file — Đọc toàn bộ nội dung bài viết của bạn
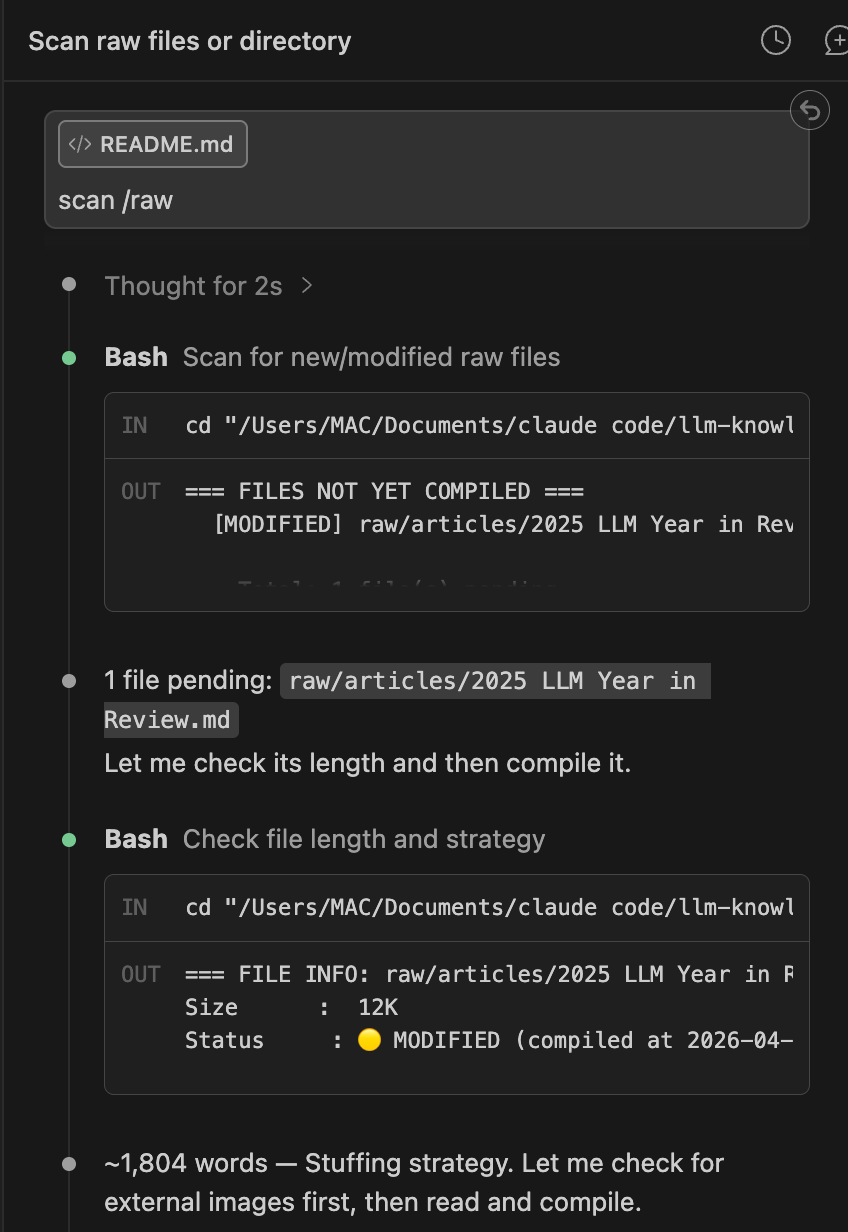
5. Tạo summary — Viết wiki/summaries/articles.md tóm tắt các paradigm shift chính của bài.
6. Tạo concept file — Trích xuất các khái niệm cốt lõi (tối đa 3–5 theo quy tắc)
7. Finalize — Chạy finalize-compile.sh với key insight để tự động

Ngoài ra, hệ thống còn cho phép một lệnh như:
Hỏi & đáp sinh báo cáo:
query: <câu hỏi ở mảng nào đó>Quét health system:
lint
Bước 4: Trình diễn đồ thị thông tin
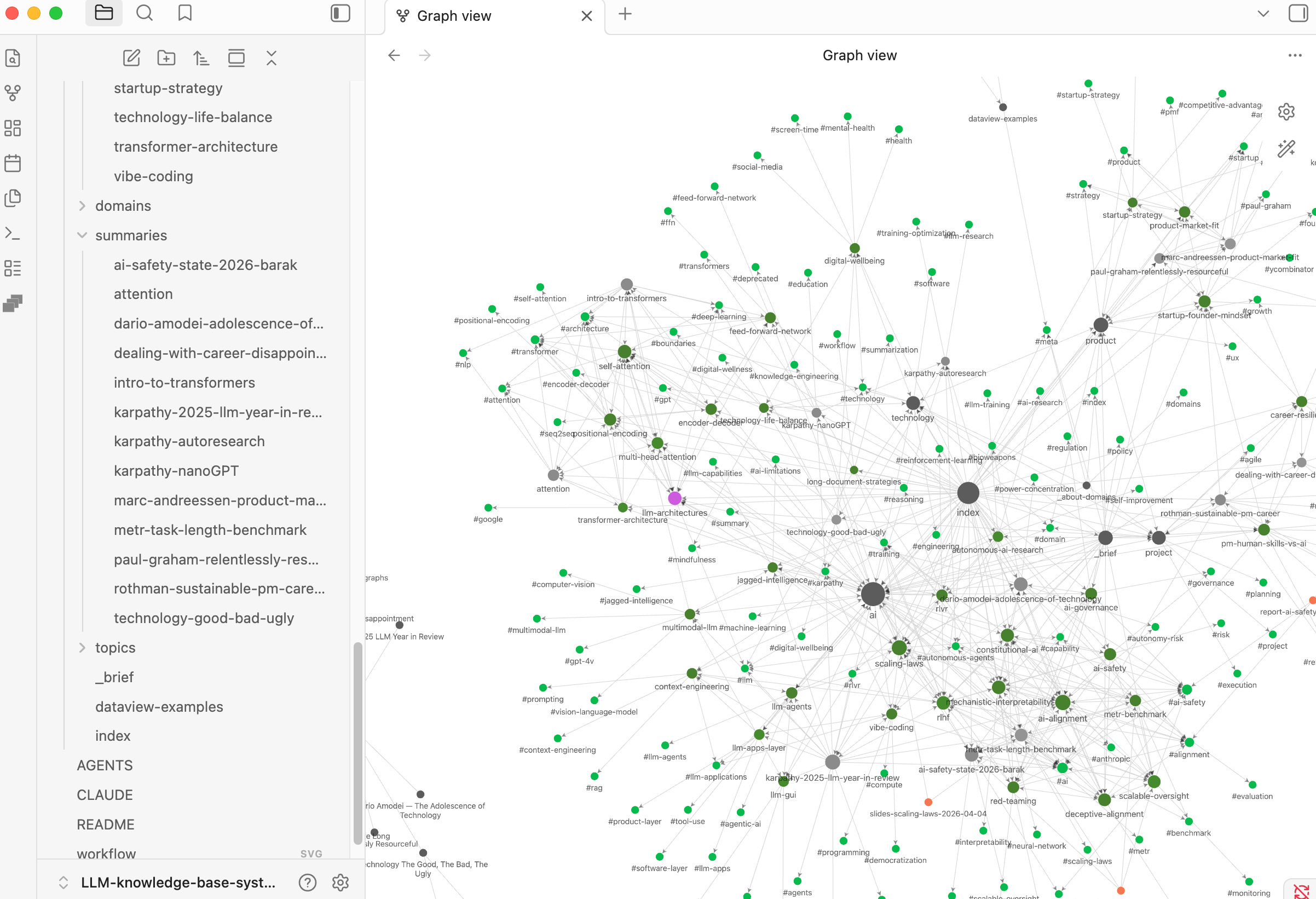
Mở hệ thống Obsidian. Chọn Open folder as vault - trỏ vào chính thư mục vừa clone. Bạn có thể dành hàng giờ ngắm nhìn những điểm chạm dữ liệu do con AI tự viết & tự liên kết sinh ra qua màn hình Graph View.
Hiện tại repos gốc thì mình đang để hướng dẫn output sẽ là Tiếng Anh do mình public trên Github, nhưng bạn có thể tự edit lại file Claude.md và Agents.md yêu cầu output bằng tiếng Việt và mức độ giải thích chi tiết mà bạn mong muốn, ví dụ bạn non-tech hoặc còn là sinh viên thì có thể yêu cầu output theo yêu cầu của bạn.
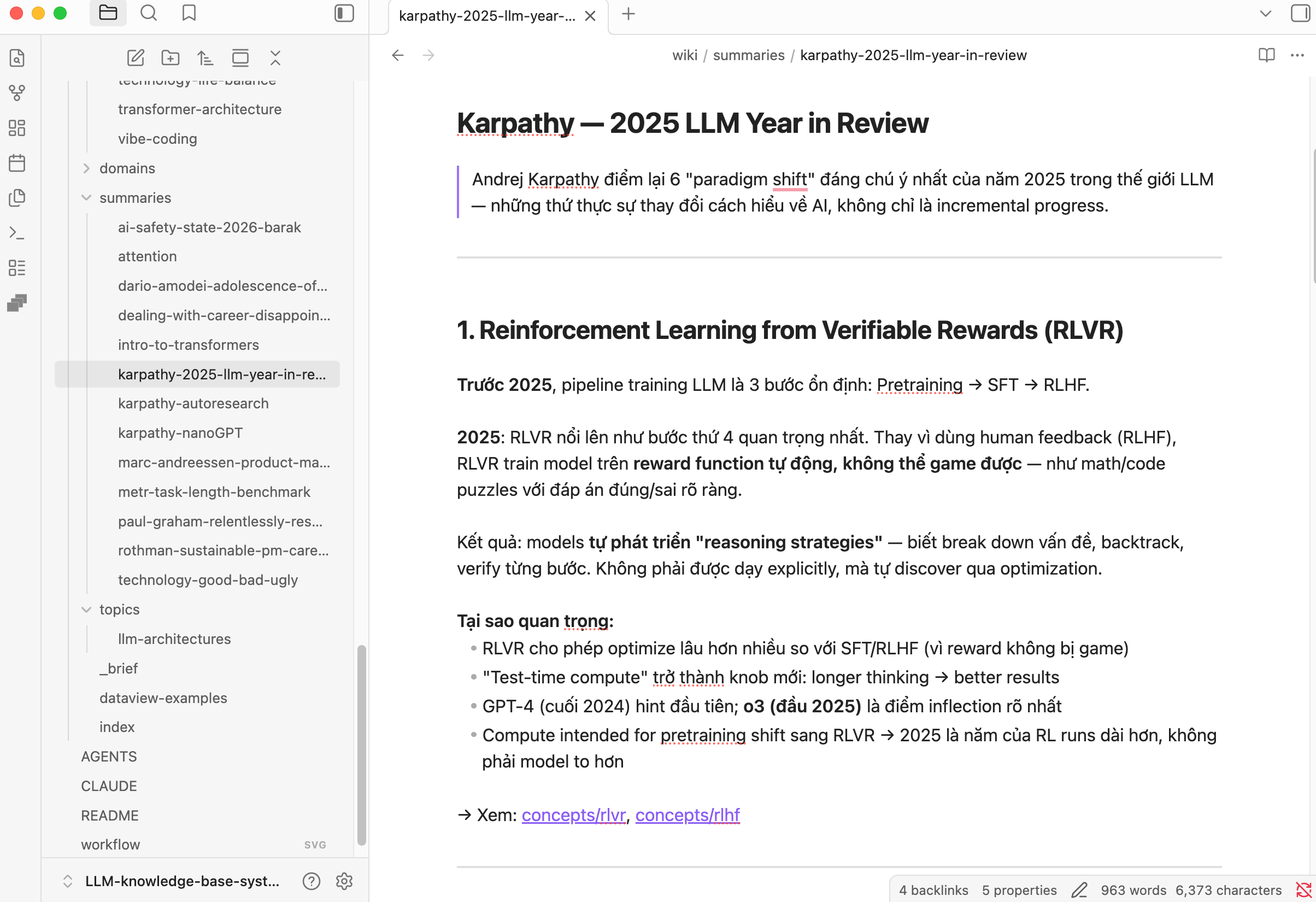
Khi hệ thống phát triển ngày càng nhiều, bạn sẽ xây dựng được một Graph View như này:
3. Hành Trình Architecture: 5 Insights Lõi
Quá trình xây dựng repo này không chỉ đơn thuần là viết vài cái prompt. Nó buộc mình phải giải quyết những bài toán cốt lõi nhất của việc thiết kế AI Agent.
Insight 1: Đừng Xây Dựng Smart AI, Hãy Xây Dựng Lazy AI
Khi mới bắt đầu, mình cho AI một cái prompt khổng lồ: “Hãy đọc file này, tóm tắt nó, xuất ra các concept, sau đó cập nhật file index, sinh ID, rồi update log file...”
Kết quả: Thảm họa. AI bị quá tải nhận thức (cognitive overload). Nó thỉnh thoảng quên bước này, định dạng sai bước kia, hoặc làm hỏng file index của tôi.
Giải pháp của mình - “The Lazy AI Checklist”: Mình nhận ra nguyên tắc vàng trong thiết kế Agent:
LLM quản lý ngữ nghĩa (semantic)
Code quản lý trạng thái (deterministic).
Mình thu hẹp task của AI xuống chỉ còn 3 bước:
Chọn chiến lược đọc.
Đọc file và xuất ra report/concepts với insight thông minh nhất.
Gọi đúng 1 hàm duy nhất:
./tools/finalize-compile.sh.
Bên trong hàm Bash script đó, hardcode của mình sẽ lo toàn bộ mớ công việc chân tay (đánh dấu file đã đọc, tự động rebuild Index, gắn tag tĩnh). Nhờ việc loại bỏ bớt sự tự do của AI trong các tác vụ lặp lại, nó có 100% tài nguyên để suy luận sâu.
LLM không giỏi làm việc lặp lại — nó giỏi suy luận. Đừng dùng LLM như một script runner. Hãy dùng nó như một “thinking engine”.
Insight 2: Adaptive Reading Engine
Bạn không thể dùng chung một phương pháp để tóm tắt một bài blog dài 3 trang và một bài báo cáo khoa học dài 100 trang của Meta. Nếu dồn tất cả vào context window, AI sẽ bị lost in the middle.
Để giải quyết, mình xây dựng bộ scan.sh có khả năng đo lường dung lượng tài liệu gốc, sau đó chủ động routing AI vào 4 chiến lược biên dịch:
Stuffing (<4,000 từ): Đọc thẳng 1 lần và tóm tắt.
Refine (4k-10k từ): Cuốn chiếu từng đoạn. Đọc phần Intro tạo khung, sau đó đọc các phần sau để bổ sung nội dung vào.
Map-Reduce (10k-25k từ): Ép AI đọc Abstract + Conclusion trước để lấy xương sống. Sau đó chia nhỏ paper ra (Map), tóm tắt từng phần, rồi tổng hợp lại (Reduce).
Hierarchical Split (>25k từ): Tách nhỏ thành từng Part riêng biệt, tóm tắt từng Part rồi mới sinh ra file Tổng hợp chung (Synthesis).
Đây chính là cách bạn “scale context window mà không cần tăng context window”.
Insight 3: Concept Explosion
Sức mạnh của Obsidian nằm ở các “Khái niệm đa dụng” (atomic concepts). Nhưng nếu bạn để LLM tự quyết định, nó sẽ tạo ra nhiều dữ liệu vô nghĩa. Ví dụ: nếu bạn để LLM tự do, nó sẽ tạo concept kiểu:
AI
System
Data
→ Thực tế không phải không có nghĩa mà lượng concepts sẽ cực kỳ nhiều nếu bạn xử lý vài trăm bài.
Để khống chế, mình đưa một Rule vào AGENTS.md: Giới hạn cứng tối đa 3-5 Core Concepts trên mỗi tài liệu. Nếu một khái niệm chỉ là yếu tố phụ, AI buộc phải giải thích nó inline (ngay trong bài) chứ không được sinh ra file mới.
Hệ thống của mình hoạt động kiểu organic. Tool lint.sh chạy ngầm sẽ liên tục đo lường: Khi nào một cụm từ xuất hiện trong hơn 10 bài viết, nó báo động yêu cầu AI xây dựng một “Domain Map of Content” (MOC) cho lĩnh vực đó. Kiến thức sẽ tự động phân rẽ ra thành từng nhánh lớn theo cách bạn hấp thụ thông tin. Tức là thực tế bạn không cần tự setup domain từ đầu, mà dựa trên những gì nạp vào wiki bạn, hệ thống sẽ detect và tạo domain khi đủ concepts.
Insight 4: Self-Healing Wiki
Đây có lẽ là tính năng làm mình tự hào nhất. Trong quá trình dọc tài liệu, AI thường xuyên tạo ra các liên kết đến những khái niệm chưa từng tồn tại trên bộ nhớ máy tính của bạn (gọi là Broken Links).
Quá trình Web Imputation diễn ra như sau:
Bạn đưa lệnh
lint, hệ thống tìm ra các từ khoá mồ côi.AI tự động kích hoạt Web Search, lên mạng tìm hiểu sâu về khái niệm đó.
Nó tổng hợp, tự viết ra một file Concept hoàn chỉnh (có trích nguồn đàng hoàng), tự bỏ đắp vào Wiki gốc.
Hệ thống tự biết nó đang thiếu kiến thức gì và chủ động đi học để đắp vào lỗ hổng đó.
Đây là lúc hệ thống chuyển từ knowledge storage → thành một knowledge organism.
Nó không chỉ lưu trữ kiến thức — nó tự biết mình thiếu gì và đi học.
Insight 5: File-Back Loop
Sự khác biệt giữa một thùng chứa PDF và một Bộ Não nằm ở khả năng lai tạo ý tưởng. Giả sử bạn bắt AI so sánh kiến trúc Transformer và MoE. Nó làm ra một bản báo cáo rất xuất sắc. Nếu quy trình dừng lại ở đây, bạn sẽ quên nó vào ngày mai.
Bước “File-back” ép AI phải trích xuất những Insight mới mẻ nhất (vừa sinh ra trong quá trình so sánh) để viết NGƯỢC trở lại vào các file concept trong hệ thống ban đầu. Mỗi một câu hỏi khó bạn đặt ra cho AI, Wiki của bạn sẽ tự động dày dặn và “sáng suốt” hơn một bậc.
Tức là khi bạn tổng hợp thông tin xong, bạn sẽ dùng lệnh query để tiến hành xây dựng các chủ đề chuyên biệt mà bạn mong muốn, trong quá trình đó, có thể sẽ lại tiếp tục tạo ra những kiến thức mới, vai trò của file-back loop sẽ giúp bạn tiếp tục cập nhật kiến thức mới vào hệ thống ban đầu.
Đây là cơ chế giúp hệ thống không chỉ lưu trữ tri thức
mà còn tiến hóa theo mỗi câu hỏi bạn đặt ra.
Lời Kết
Có thể bạn không cần một hệ thống RAG phức tạp. Bạn chỉ cần một hệ thống biết: đọc, hiểu và tự viết lại tri thức cho bạn.
Đây là một sự dịch chuyển thú vị: Từ Folder Management sang Agent Orchestration.
Toàn bộ hệ thống, triết lý, script và template đã được mình Open Source với License MIT. Nếu bạn hứng thú với việc đưa AI vào quy trình phân tích và hấp thụ tri thức, bạn chỉ cần Clone nó về, bật giao diện của Claude Code lên và bỏ file vào thư mục /raw.
🔗 Github Repo: hoadoan1997/llm-knowledge-base
Hệ thống được tối ưu hóa hiển thị tuyệt đẹp trên Obsidian. Chào mừng các bạn vào fork, trải nghiệm và đóng góp Pull Request. Nếu thấy bài tiếp cận này hữu ích, hãy để lại cho dự án một Star ⭐ nhé!
(Hãy comment nếu bạn có ý tưởng nào để mở rộng thêm cho workflow PKM tương lai này!)
Hay quá ạ bác ạ
Nghe thú vị quá. Cảm ơn bạn, mình sẽ thử