
Context & Harness Engineering
Why Prompt Engineering is not enough — and how Context & Harness turn AI into real workflows

Trong vài năm qua, khi nói về AI, phần lớn cuộc thảo luận thường xoay quanh một câu hỏi quen thuộc:
Làm sao viết prompt tốt hơn?
Đó là một câu hỏi hợp lý.
Prompt Engineering từng là điểm khởi đầu quan trọng để mọi người khai thác LLM tốt hơn. Nhưng khi AI bắt đầu đi vào công việc thực tế — từ coding, research, debugging, viết tài liệu, vận hành workflow, cho đến tự động hóa nhiều bước thì một sự thật dần lộ ra:
Vấn đề không còn chỉ là ra lệnh cho model thế nào.
Vấn đề là làm sao để model có đủ context đúng, được đặt trong một khung vận hành đúng, và có thể hoàn thành công việc dài hơi mà không trôi, không quên, không tự ảo tưởng rằng mình đã xong.
Đó chính là lúc ba khái niệm bắt đầu trở nên quan trọng hơn rất nhiều:
AI Agents
Context Engineering
Harness Engineering
Và nếu đi thêm một bước nữa, chúng ta sẽ thấy một chuyển động rất rõ: từ các prompt rời rạc sang workflow có thể scale và bài viết này mình chia sẻ lại hành trình và kinh nghiệm của bản thân mình trong 1 năm qua.
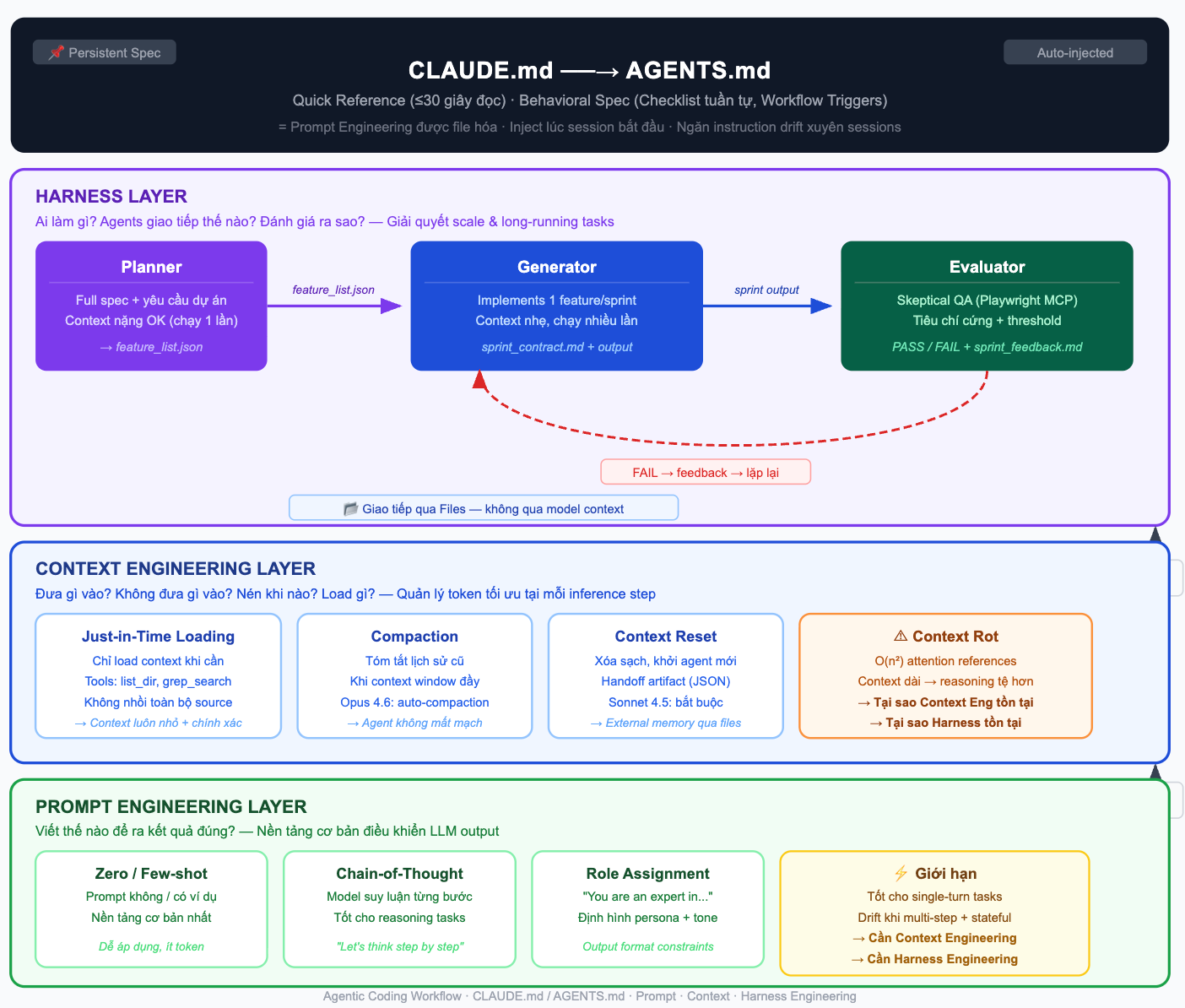
1. AI Agent là gì, và vì sao nó khác chatbot?
Một chatbot thông thường chủ yếu hoạt động theo mô hình:
Ask → Answer
Trong khi đó, một AI Agent không chỉ trả lời. Nó nhận nhiệm vụ, tự chia nhỏ vấn đề, sử dụng công cụ, ghi nhớ trạng thái, rồi tiếp tục ra quyết định để hoàn thành một chuỗi công việc nhiều bước. Một agent đúng nghĩa thường có 4 thành phần cốt lõi:
tools
planning
memory
và autonomy.
Nói đơn giản hơn:
Chatbot giỏi phản hồi
Agent giỏi thực thi
Sự khác biệt này rất quan trọng. Chatbot thường stateless, tương tác ngắn, rất ít công cụ; còn AI Agent có thể làm việc xuyên nhiều giờ hoặc nhiều ngày, có trạng thái, có quyền truy cập toolchain, và có thể tự quyết định bước tiếp theo.
Đây là lý do vì sao những công cụ như Claude Code không nên được nhìn như “chatbot biết code”. Ở mức vận hành, nó gần hơn với một agent đang làm việc trong production: có nhiều tools, có khả năng phối hợp sub-agent, có cơ chế xử lý lỗi, và có cách duy trì tiến trình dài hạn.
2. Nhưng tại sao agent mạnh vẫn hay làm sai?
Câu trả lời nằm ở hai giới hạn nền tảng.
Thứ nhất, model không thật sự hiểu toàn bộ hệ thống nếu context được nạp vào sai cách.
Thứ hai, model không tự nhiên biết cách làm việc ổn định trong môi trường nhiều bước, nhiều tool, nhiều lần kiểm tra.
Chính vì vậy, agent mạnh đến đâu cũng bị giới hạn bởi hai bài toán gốc:
Context Engineering: quản lý thông tin nào được đưa vào model, theo cách nào, vào thời điểm nào
Harness Engineering: thiết kế hạ tầng và quy trình điều phối cách agent hoạt động trong thực tế
Nếu cần nói ngắn gọn:
Context Engineering giải quyết chất lượng suy luận
Harness Engineering giải quyết độ tin cậy khi thực thi
Đây không phải hai chủ đề tách rời. Chúng bổ sung trực tiếp cho nhau.
3. Prompt Engineering: vẫn hữu ích, nhưng không còn đủ
Trước khi đi sâu hơn, cần nói công bằng rằng Prompt Engineering không hề mất giá trị.
Một prompt tốt vẫn giúp:
giảm ambiguity
định dạng output rõ hơn
buộc model tập trung vào mục tiêu chính
tiết kiệm vài vòng sửa qua sửa lại
Ví dụ, thay vì viết:
Analyze this issue
Ta nên viết:
Analyze this issue and provide:
Summary
Root cause with evidence
Recommended fix
Client-facing explanation
Chỉ riêng việc này cũng đã nâng chất lượng lên đáng kể.
Nhưng vấn đề là: Prompt Engineering chỉ mạnh khi bài toán còn tương đối đơn lẻ. Khi công việc bắt đầu có những đặc điểm như:
nhiều bước
nhiều file
nhiều audience
nhiều tool
nhiều trạng thái cần duy trì
cần consistency lâu dài
Thì prompt thôi không đủ nữa. Bạn có thể viết prompt ngày càng dài hơn, chi tiết hơn, “thông minh” hơn. Nhưng đến một ngưỡng nào đó, chất lượng vẫn sẽ không ổn định. Lý do không phải vì prompt chưa đủ hay, mà vì hệ thống xung quanh model chưa được thiết kế đúng.
Đó là nơi Context Engineering và Harness Engineering bước vào.
4. Context Engineering: nghệ thuật không chỉ là đưa gì vào, mà còn là không đưa gì vào
Đây là một trong những điểm quan trọng nhất mà mình muốn chia sẻ.
Trong cách nghĩ thông thường, khi agent làm chưa tốt, nhiều người sẽ phản xạ:
thêm context vào đi
Nhưng có một vấn đề nền tảng hơn: context rot. Khi context window dài ra, attention bị pha loãng, khiến khả năng suy luận suy giảm. Vì thế, “nhồi càng nhiều càng tốt” không phải chiến lược đúng.
Đây là insight rất đáng nhớ:
Chọn những gì không nên đưa vào context quan trọng không kém gì chọn những gì nên đưa vào.
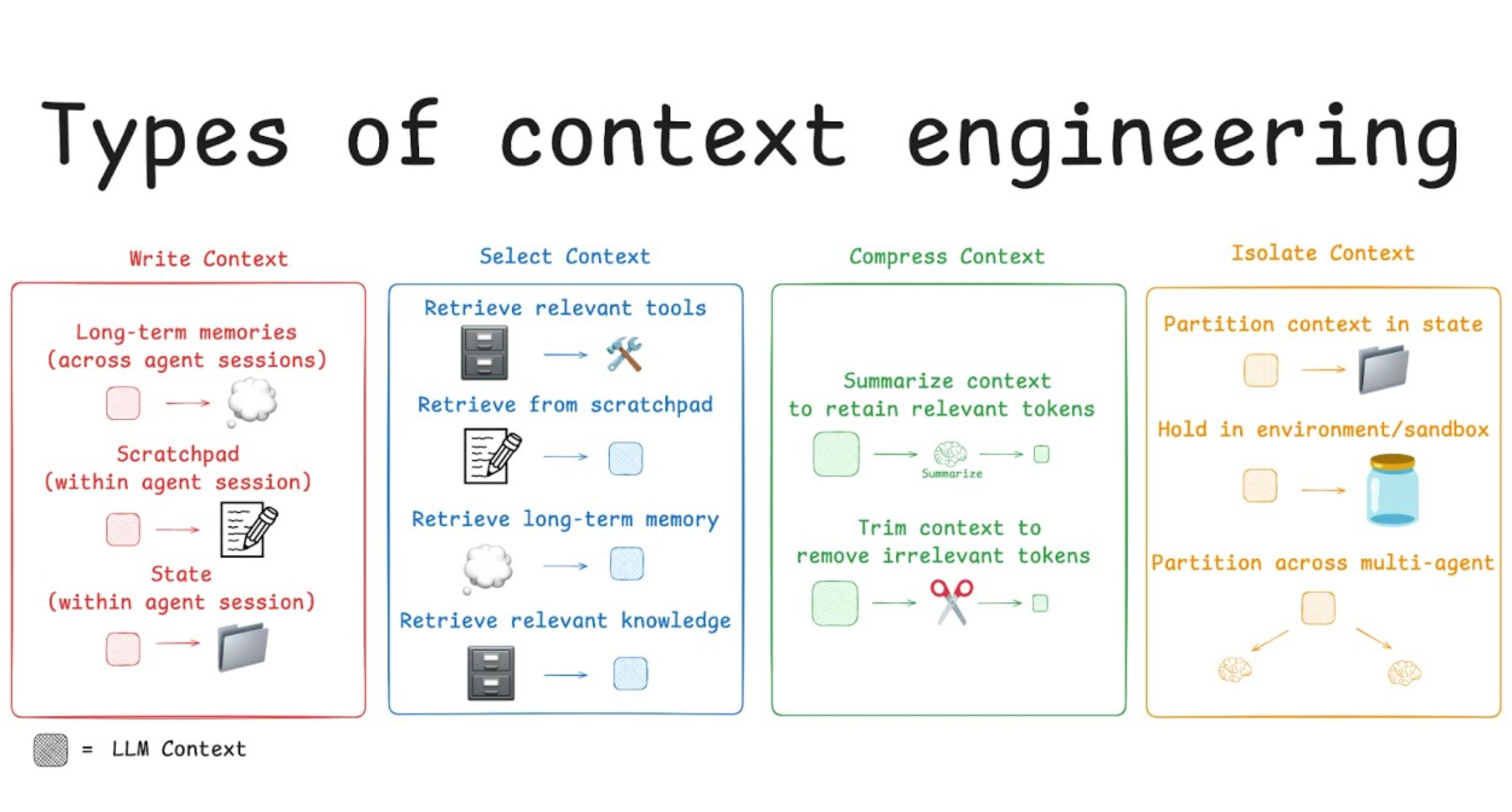
Ba trụ cột của Context Engineering
Có ba trụ cột khá rõ ràng.
Thứ nhất, system prompts phải đúng cao độ.
Không quá chung chung để model bị mơ hồ, nhưng cũng không quá cứng đến mức dễ vỡ khi model thay đổi. Phần system prompt nên mang tính nguyên tắc và ranh giới rõ ràng.
Thứ hai, tools phải sạch.
Nếu có quá nhiều tool trùng chức năng hoặc không rõ mục đích, model sẽ bị nhiễu trong việc chọn cách hành động. Claude Code dùng cơ chế deferred tools để ẩn bớt tool và chỉ “discover” khi cần.
Thứ ba, context nên được nạp “just in time”.
Thay vì cố load toàn bộ codebase hay toàn bộ project notes, hãy để agent có công cụ đi tìm đúng thông tin đúng lúc. Ví dụ dùng grep, list_dir, search, file lookup thay vì ép model ôm toàn bộ mã nguồn ngay từ đầu.
Nói cách khác:
Context Engineering không phải là nạp thật nhiều thông tin.
Nó là thiết kế để model chạm đúng thông tin vào đúng thời điểm.
5. CLAUDE.md: lớp Context Engineering cơ bản nhưng cực kỳ thực dụng
Nếu chuyển từ lý thuyết sang ứng dụng thực tế, thì Claude.md là một ví dụ rất điển hình của Context Engineering.
Claude.md không nên bị hiểu như một chỗ để nhồi tất cả prompt mẫu vào.
Vai trò đúng của nó gần hơn với:
rule nền
working conventions
communication defaults
assumptions được cấm
style xử lý chuẩn của team
Tức là, Claude.md trả lời câu hỏi:
Trong môi trường làm việc này, AI nên hành xử như thế nào?

Ví dụ những gì nên nằm ở đó:
không được assume environment nếu chưa xác nhận
phải verify screenshot/log/CSV trước khi kết luận
output mặc định là ngôn ngữ như nào, đơn giản
internal/dev docs mặc định là tiếng Anh, có cấu trúc
frontend patch phải read actual DOM hoặc template trước khi fix
Những thứ này rất hợp với tinh thần Context Engineering, bởi chúng giúp ổn định “bối cảnh làm việc” qua nhiều phiên, thay vì mỗi lần lại giải thích lại từ đầu.
Nói ngắn gọn:
Claude.md là nơi externalize những thứ mà nếu để model tự đoán, nó sẽ đoán sai hoặc không nhất quán.
6. AGENTS.md: khi context không còn đủ, ta cần workflow
Nếu Claude.md là luật nền, thì AGENTS.md gần hơn với một playbook.
Vai trò của nó là mô tả:
workflow chuẩn
checklist nhiều bước
thứ tự các phase
file nào phải update
điều kiện nào mới được xem là done
Đây là bước chuyển rất quan trọng, bởi vì rất nhiều lỗi của agent không nằm ở phần “ý tưởng chính”, mà nằm ở phần “quy trình bị bỏ sót”.
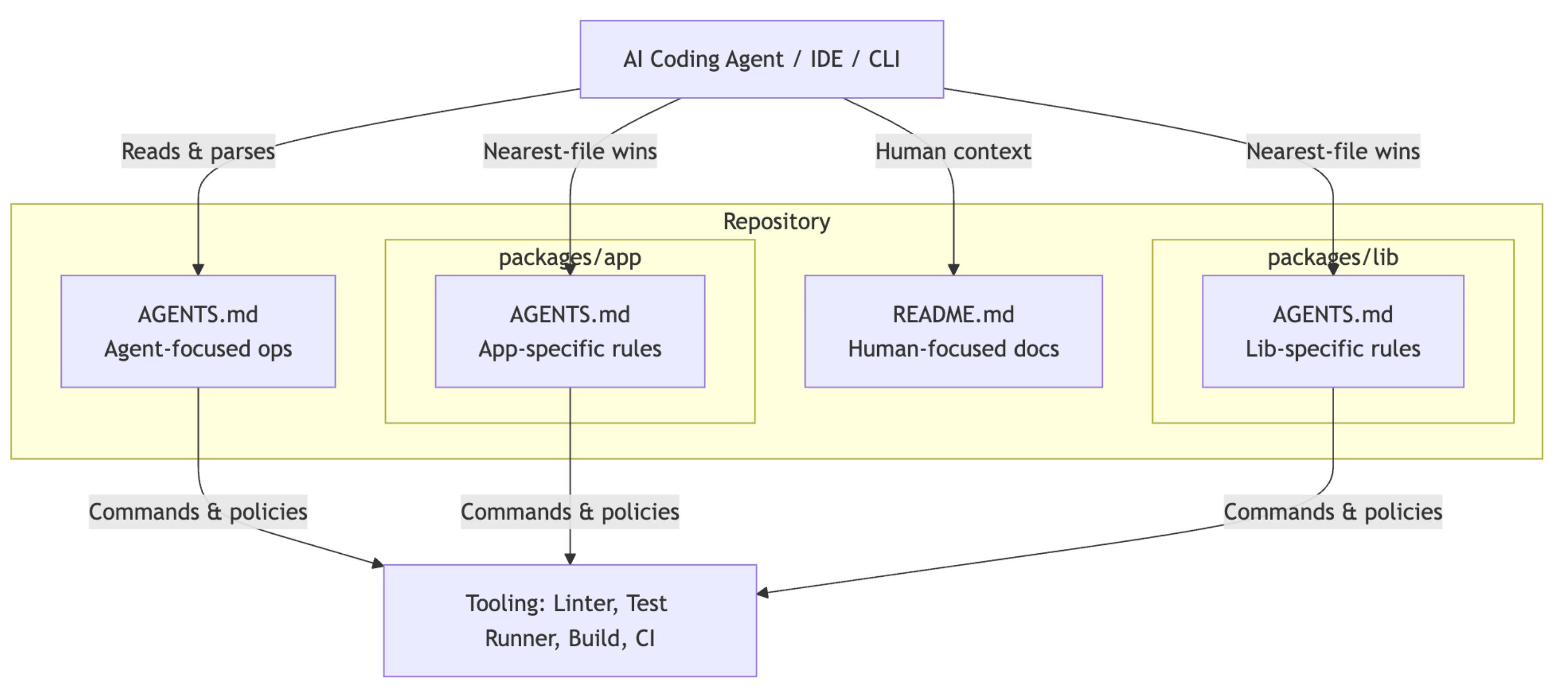
Ví dụ rất điển hình:
viết article xong nhưng quên update index.md
compile wiki xong nhưng quên _brief.md
phân tích xong nhưng chưa cross-reference nội dung liên quan
sửa code xong nhưng chưa chạy test hoặc validation
Đây là loại lỗi khiến output trông có vẻ xong, nhưng thực tế chưa xong.
Và đó là lúc AGENTS.md phát huy giá trị. Nó trả lời câu hỏi:
Với loại công việc này, agent phải đi qua những bước nào, và những bước nào tuyệt đối không được bỏ?
Nếu Claude.md là lớp rule ổn định, thì AGENTS.md là lớp vận hành.
7. Context Engineering có một giới hạn tự nhiên: context rot buộc ta phải nghĩ đến Harness
Đây là điểm mà cần lưu ý: không dừng ở chuyện “quản lý context cho một agent”, mà đi tiếp đến câu hỏi:
Nếu một agent phải làm việc dài hạn, nhiều bước, nhiều giờ, thì chỉ tối ưu context có đủ không?
Câu trả lời là không.
Bởi vì ngoài context rot, agent còn gặp hai failure mode kinh điển mà rất rõ:
Premature completion — agent tự nghĩ là mình đã xong quá sớm.
Scope explosion — agent cố làm quá nhiều thứ cùng lúc và mất kiểm soát.
Hai lỗi này không được giải quyết chỉ bằng prompt hay context tốt hơn. Chúng cần một lớp cao hơn:
một khung vận hành để agent biết khi nào bắt đầu, làm trong phạm vi nào, ai đánh giá, lưu trạng thái ở đâu, và tương tác với nhau ra sao.
Đó chính là Harness Engineering.
8. Harness Engineering: thiết kế môi trường làm việc cho agent
Nếu Context Engineering là “đưa đúng thông tin vào bộ não”, thì Harness Engineering là “thiết kế cả cơ thể và môi trường làm việc cho bộ não đó”.
Nói cách khác, harness là tất cả những thứ bao quanh model để giúp model làm việc được trong thực tế:
lifecycle
orchestration
evaluator
tool invocation
checkpoint
state storage
retry logic
testing loop
artifact handoff
Đây là nơi chúng ta bắt đầu thấy những thứ như:
Planner / Generator / Evaluator
feature_list.json
progress logs
scripts
sprint contract
test harness
file-based IPC
hooks sau Write/Edit
Playwright/Puppeteer để kiểm tra app thật
Những thứ này nghe có vẻ kỹ thuật, nhưng ý nghĩa của nó rất thực dụng:
Harness giúp agent bớt “nói có vẻ đúng”
và tiến gần hơn tới việc “làm đúng trong hệ thống thật”.
9. Một trong những insight giá trị nhất: self-evaluation bias
Trong phần Harness Engineering, có một pattern rất đáng chú ý:
Agent tự đánh giá chính mình gần như luôn thiên về lạc quan.
Đây là lý do vì sao một hệ thống chỉ có “generator” rất dễ thất bại. Model viết code xong, đọc lại, rồi tự tin rằng tính năng đã chạy. Nhưng thực tế thì UI vẫn lỗi, flow vẫn gãy, edge case vẫn chưa qua.
Vì vậy, một trong những harness pattern mạnh nhất là:
Generator tạo ra output
Evaluator đánh giá độc lập output đó
Một mô hình 3-agent gồm Planner, Generator, Evaluator, trong đó Evaluator có thể dùng Playwright để click qua app thật như người dùng thật. Điều này cực kỳ quan trọng, vì nó đưa việc đánh giá từ “ngôn ngữ” sang “thực nghiệm”.
Đây là một bước nhảy chất lượng rất lớn.
Không phải “code nhìn có vẻ đúng”
mà là “ứng dụng thật chạy đúng”
Nếu chỉ chọn một component có ROI cao nhất để thêm vào harness, báo cáo cũng gợi ý rất rõ: hãy thêm evaluator độc lập.
10. Context Engineering và Harness Engineering thực ra là hai mặt của cùng một vấn đề
Đây có lẽ là phần cốt lõi nhất trong toàn bài viết này.
Không nên xem Context Engineering và Harness Engineering là hai lĩnh vực tách rời, mà là hai lớp đang giải cùng một bài toán ở hai cấp độ khác nhau.
Context Engineering hỏi: đưa gì vào model?
Harness Engineering hỏi: đặt model ở đâu trong hệ thống?
Có ba điểm giao nhau rất mạnh mà mình muốn chia sẻ
1. Context rot chính là lý do phải có harness
Nếu context không bị suy thoái khi kéo dài, về lý thuyết một agent duy nhất có thể đủ cho rất nhiều công việc. Nhưng vì context rot tồn tại, ta buộc phải:
compact
reset
ghi notes
tách agent
cô lập context theo vai trò
Nghĩa là chính giới hạn của context đã tạo ra nhu cầu thiết kế harness.
2. Harness quyết định cách context được phân phối
Planner nhận full spec.
Coding agent chỉ nhận phần việc hiện tại.
Evaluator nhận tiêu chí đánh giá và quyền truy cập app chạy thật.
Tức là, ở cấp hệ thống, Harness Engineering cũng chính là Context Engineering ở quy mô lớn hơn.
3. Cả hai cùng thay đổi theo năng lực model
Khi model mạnh hơn:
prompt có thể bớt chi tiết hơn
model tự tìm đúng tool tốt hơn
context reset có thể ít cần hơn
một số harness components có thể bị loại bỏ
Nhưng báo cáo cũng nhấn mạnh một insight rất hay:
Không gian harness thú vị không biến mất khi model tốt hơn — nó chỉ dịch chuyển lên tầng cao hơn.
Đây là một nhận định rất đúng. Model mạnh hơn không làm hệ thống biến mất; nó chỉ cho phép ta đẩy tự động hóa lên những bài toán phức tạp hơn.
11. Từ đây, ta quay lại câu chuyện “prompt rời rạc đến workflow”
Đến đây thì bức tranh đã rõ.
Trong giai đoạn đầu, mọi người thường làm việc với AI theo kiểu:
có task thì viết prompt
có bug thì prompt bug
có report thì prompt report
có issue thì prompt issue
Cách này không sai. Nhưng nó có giới hạn rất rõ:
không nhất quán
phụ thuộc vào trí nhớ của người prompt
dễ bỏ sót bước
khó scale cho team
khó tái sử dụng
càng phức tạp càng dễ trôi
Đó là lý do vì sao bài toán thực sự không còn là “viết prompt sao cho hay”, mà là:
làm sao biến những prompt rời rạc thành một workflow có thể lặp lại, tái dùng, và đáng tin hơn theo thời gian
Và đây chính là nơi các lớp bắt đầu ăn khớp với nhau:
Claude.md
Chứa rule nền, context ổn định, behavioral defaults.
AGENTS.md
Chứa playbook, process, checklist, định nghĩa done.
SKILL.md
Chứa workflow tái sử dụng cho một loại việc cụ thể: Jira analysis, merchant support, TDD bugfix, wiki pipeline…
Harness
Chứa toolchain, hook, evaluator, scripts, validators, MCP, browser automation, test loops.
Task prompt
Chứa dữ liệu cụ thể của phiên hiện tại: ticket nào, URL nào, issue nào, output cho ai.
Khi năm lớp này được phân tách rõ, AI bắt đầu chuyển từ “một cái chat interface rất mạnh” thành “một thành phần làm việc trong hệ thống”.
12. Vậy practical takeaway là gì?
Nếu phải rút ra các bài học hành động từ bài viết này, mình sẽ tóm gọn như sau.
Một, bắt đầu bằng Context Engineering trước khi mơ đến multi-agent
Tối ưu một agent đơn thật tốt trước:
rule rõ
tool gọn
context vừa đủ
just-in-time retrieval
note-taking có cấu trúc
Hai, chỉ thêm harness khi một agent đơn bắt đầu bộc lộ failure mode
Khi agent:
hay quên
tự đánh giá sai
dừng sớm
làm lan sang quá nhiều việc
thì mới là lúc cần tách vai trò, thêm evaluator, thêm checkpoint.
Ba, evaluator là component có ROI cao nhất
Nếu bạn chỉ thêm được một thứ, hãy thêm một evaluator độc lập. Đây là cách nhanh nhất để chống self-evaluation bias.
Bốn, file-based handoff thường ổn định hơn shared context
Thay vì bắt nhiều agent “cùng nhớ một thứ”, hãy để chúng giao tiếp qua artifact rõ ràng: JSON, progress logs, notes, reports.
Năm, kiểm tra end-to-end quan trọng hơn việc chỉ nhìn code
Một system AI biết viết code chưa chắc là một system AI biết tạo ra thứ chạy được. Muốn vượt qua ranh giới đó, cần test thật, click thật, validate thật.
13. Kết luận: tương lai không nằm ở prompt dài hơn, mà ở hệ thống tốt hơn
Điều thú vị nhất mà cá nhân mình cảm nhận hiện tại đó là thế giới AI đang cho thấy rất rõ một sự chuyển pha.
Ban đầu, AI được nhìn như một công cụ trả lời.
Sau đó, nó được nhìn như một công cụ biết làm việc.
Nhưng khi bước vào sản xuất thật, AI chỉ trở nên hữu ích bền vững nếu được đặt trong một hệ thống được thiết kế đúng.
Từ góc nhìn đó:
Prompt Engineering giúp model bắt đầu
Context Engineering giúp model hiểu đúng
Harness Engineering giúp model làm việc được trong thực tế
Workflow design giúp mọi thứ có thể scale
Và đó có lẽ là điểm quan trọng nhất.
Tương lai của việc làm việc với AI không phải là viết prompt ngày càng dài.
Tương lai là xây được những hệ thống trong đó AI có context đúng, có harness đúng, có evaluator đúng, và có workflow đủ rõ để lặp lại mà không sụp đổ.
Hay nói ngắn gọn hơn:
Prompt là điểm bắt đầu.
Context là điều kiện để suy luận đúng.
Harness là điều kiện để thực thi đáng tin.
Workflow là thứ biến tất cả những điều đó thành năng lực thật trong công việc hàng ngày.
Cảm ơn bạn đã đọc tới đây. Chúc bạn một ngày tốt lành!
bài này hay điên ><