
AI Safety
AI đang mạnh lên nhanh hơn tốc độ chúng ta học cách kiểm soát nó

Hôm nay mình đọc bài viết rất hay trên X của tác giả Boaz Barak chia sẻ về “The state of AI safety in four fake graphs” và cảm giác đầu tiên là: bài này rất đơn giản, nhưng lại mô tả đúng một sự mất cân bằng đang ngày càng rõ.
Boaz gọi đó là 4 “fake graphs” vì đây không phải chart học thuật với dataset đầy đủ, mà là 4 hình vẽ tay để tóm tắt trực giác của ông về AI safety ở đầu năm 2026. Nhưng chính vì đơn giản, nó lại chạm rất trúng vấn đề.
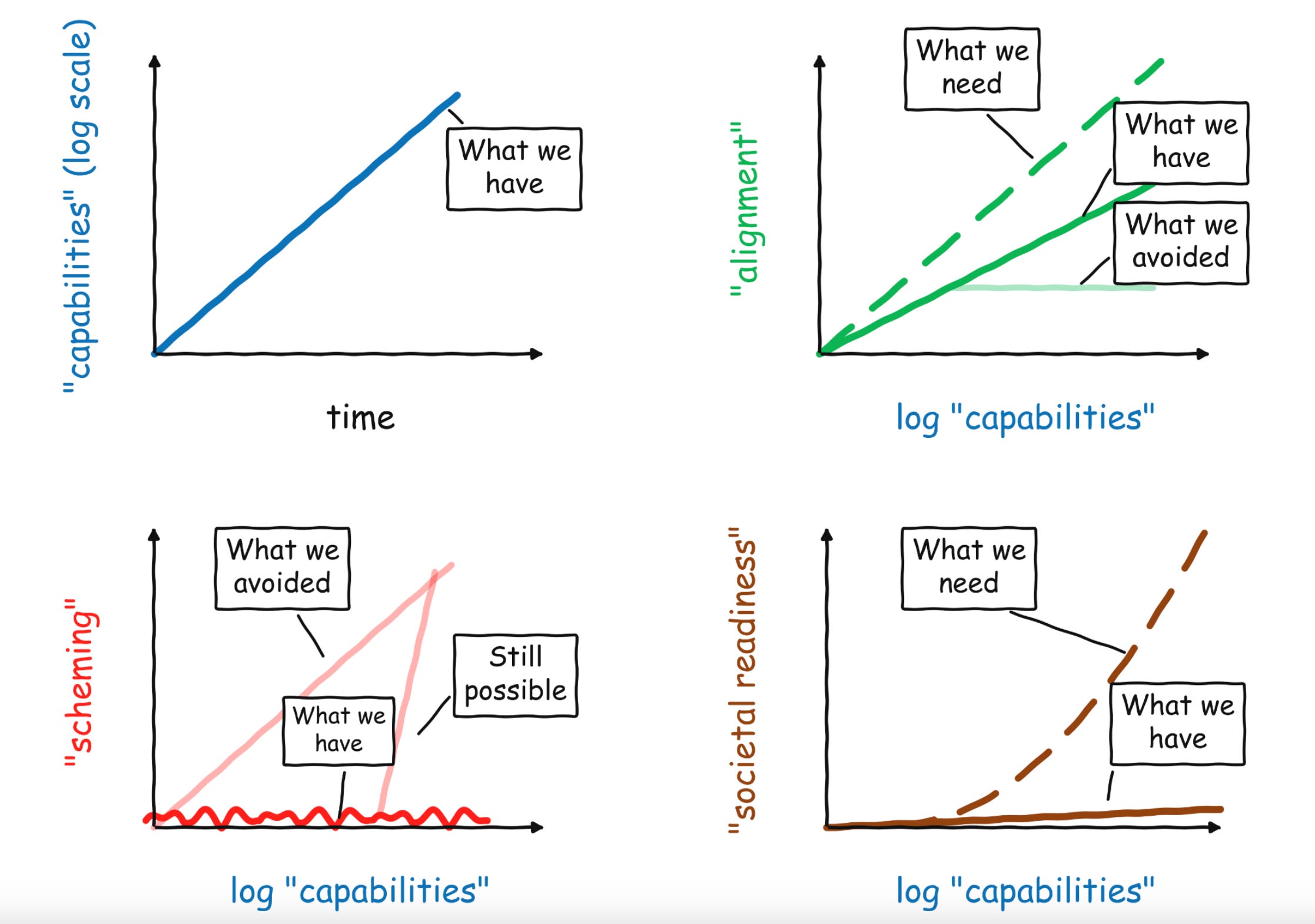
Điểm mình thấy đáng suy nghĩ nhất là thế này:
AI đang tăng capability rất nhanh. Nhưng alignment, governance, và societal readiness lại không tăng kịp theo tốc độ đó.
Và càng research thêm, mình càng thấy đây không còn là một cảm giác mơ hồ nữa. Nó đang được phản ánh bởi cả dữ liệu về capability progress, lẫn những cảnh báo ngày càng rõ từ chính các chuyên gia hàng đầu trong ngành.
1. Điều đang tăng nhanh nhất lúc này là Capability
Boaz mở đầu bằng ý mà giờ gần như ít ai còn phủ nhận: năng lực của AI vẫn đang tăng rất nhanh, và xu hướng đó chưa hề có sự chậm lại, thậm chí còn tăng nhanh hơn. Ông nhắc thẳng đến “METR graph”, và đây không phải là một hình minh hoạ vu vơ. Trong nghiên cứu của METR, nhóm tác giả đề xuất đo khả năng của AI bằng “task-completion time horizon” — tức là AI có thể hoàn thành được những task mà con người thường mất rất lâu để làm. Kết quả họ công bố cho thấy mốc này đã tăng theo xu hướng gần như hàm mũ trong nhiều năm, với thời gian nhân đôi khoảng 7 tháng; trong cập nhật đầu 2026, METR nói các model mới hơn vẫn tiếp tục bám khá sát xu hướng lịch sử này.
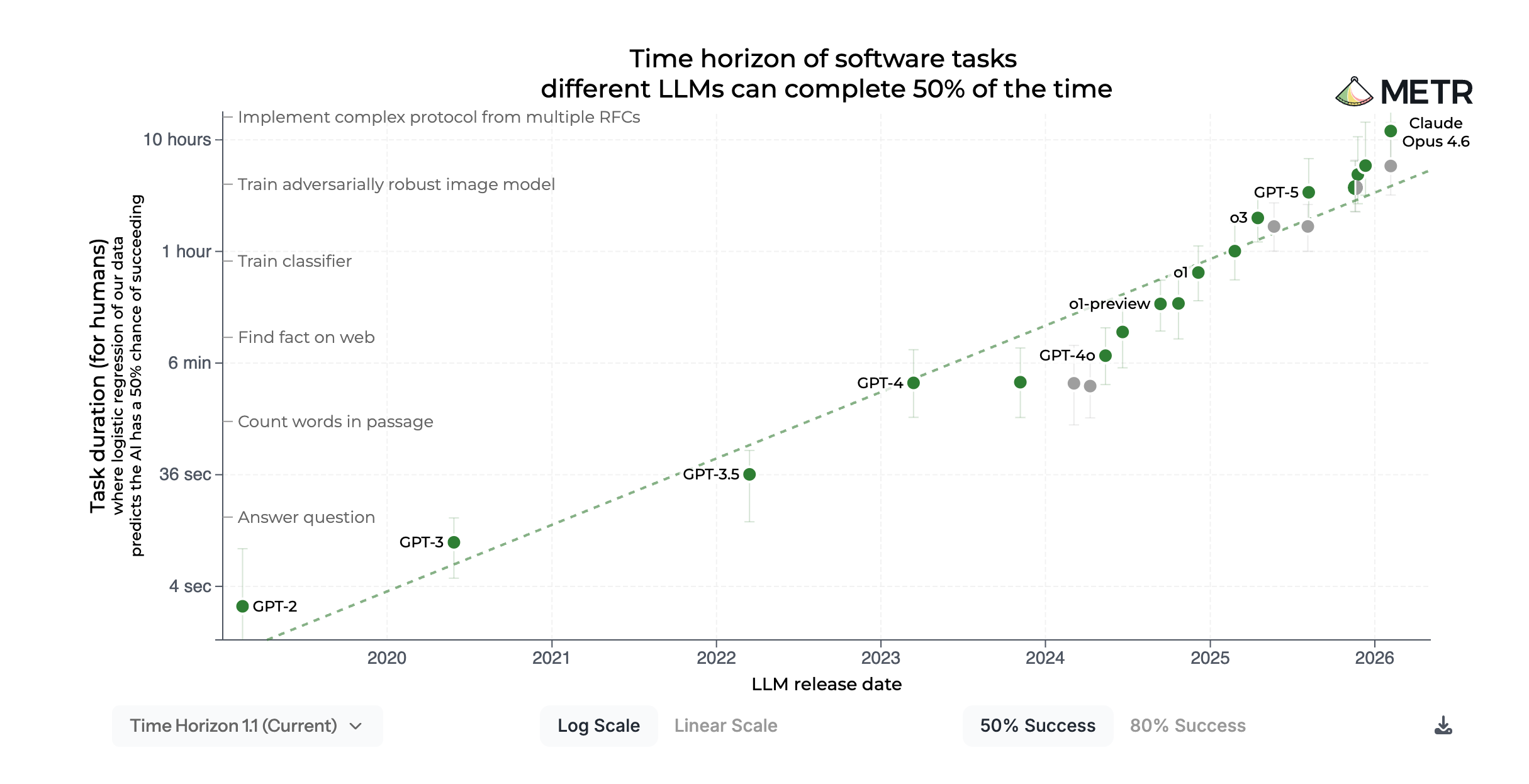
Con số đó đáng chú ý ở chỗ nó dịch chuyển “AI mạnh hơn” thành một đơn vị rất dễ hiểu: AI đang dần xử lý được những công việc vốn trước đây lấy của con người nhiều thời gian hơn. Không chỉ benchmark tăng. Không chỉ model trả lời hay hơn. Mà khoảng “thời lượng công việc” AI có thể gánh đang được kéo dài ra rất nhanh. METR thậm chí còn lưu ý rằng trong một số phân tích theo domain, tốc độ này có thể đã tăng nhanh hơn nữa ở giai đoạn gần đây.
Nếu nhìn thêm từ phía kinh tế và hệ sinh thái, tốc độ tăng này còn được khuếch đại bởi chi phí giảm và khả năng tiếp cận tăng. Stanford AI Index 2025 ghi nhận rằng chi phí suy luận cho một hệ thống đạt mức GPT-3.5 đã giảm hơn 280 lần từ tháng 11/2022 đến tháng 10/2024; trong cùng thời gian, open-weight models cũng rút ngắn khoảng cách hiệu năng với closed models trên một số benchmark từ 8% xuống còn 1.7%. Nói cách khác, không chỉ frontier labs mạnh lên — mà AI đủ mạnh cũng đang rẻ hơn, dễ tiếp cận hơn, và lan rộng nhanh hơn.
Và nếu nhìn vào vài tháng gần đây, cảm giác “capability jump” này còn rõ hơn. Anthropic đã phát hành Claude Opus 4.6 vào tháng 2/2026 như một hybrid reasoning model cho knowledge work, coding và agents, trong khi OpenAI công bố GPT-5.4 vào ngày 5/3/2026 như model frontier mạnh nhất của họ cho professional work, với bước nhảy đáng kể ở coding, computer use và long-horizon deliverables. Cùng lúc đó, OpenClaw xuất hiện như một “open agent platform” chạy trên máy người dùng, cho thấy đột phá bây giờ không chỉ nằm ở model thuần tuý mà còn ở tầng agent runtime: AI không chỉ trả lời tốt hơn, mà còn bắt đầu “làm việc” tốt hơn trong môi trường thật, qua tool use, multi-step execution và tích hợp trực tiếp vào workflow hằng ngày.
Đây là lý do mình nghĩ biểu đồ đầu tiên của Boaz rất “đắt”. Nó không chỉ nói rằng AI tốt hơn. Nó nói rằng AI đang tăng tốc trong khi ngưỡng phổ cập của AI cũng đang giảm xuống. Một công nghệ vừa mạnh lên vừa rẻ đi, lại vừa dễ được đóng gói thành các hệ thống agentic có thể hành động trong thế giới thực, sẽ tạo áp lực lên toàn bộ hệ thống xung quanh nó lớn hơn nhiều so với một công nghệ chỉ mạnh lên đơn thuần.
2. Alignment có tiến bộ, nhưng chưa đủ để theo kịp stakes
Đây là đoạn mà mình thấy nhiều người ngoài ngành hay hiểu nhầm nhất. Nói về AI safety, nhiều người hay rơi vào tư duy nhị phân: hoặc an toàn, hoặc không an toàn. Nhưng thực tế không như vậy.
Boaz không hề bảo alignment đứng yên. Ngược lại, ông nói rõ là có good news in alignment: các model hiện nay aligned hơn trên nhiều thước đo, bao gồm cả spec compliance. Nhưng luận điểm cốt lõi của ông là: đường tăng của alignment vẫn thấp hơn đường tăng của cái chúng ta cần khi capability leo dốc quá nhanh.
Nếu chuyển sang ngôn ngữ đời thường, vấn đề là thế này: bạn đang có một “nhân viên” ngày càng giỏi hơn, làm được nhiều việc hơn, nhanh hơn, thậm chí chủ động hơn. Đúng là người đó cũng ngoan hơn một chút, dễ điều khiển hơn một chút. Nhưng nếu năng lực tăng gấp nhiều lần, còn khả năng giám sát và đảm bảo làm đúng chỉ tăng nhẹ, thì rủi ro tổng thể vẫn tăng.
Điểm này cũng được phản ánh trong cách các lab lớn đang formalize safety. OpenAI nói trong Preparedness Framework 2025 rằng họ muốn đo và chặn các năng lực có thể gây “severe harm” trước khi triển khai rộng. Anthropic thì ở Responsible Scaling Policy v3 bổ sung thực hành Risk Reports và hệ thống kiểm soát bài bản hơn. Google DeepMind cũng liên tục cập nhật Frontier Safety Framework của mình. Chỉ riêng việc các lab đều phải dựng framework riêng để theo dõi frontier risks đã cho thấy một thực tế: capability đã đi xa đến mức việc “tin vào good intentions” không còn đủ nữa.
Nhưng ở đây có một nghịch lý. Việc các framework đó tồn tại là tín hiệu tốt, vì ít nhất ngành đã nghiêm túc hóa safety. Tuy nhiên, sự tồn tại của framework cũng đồng thời là bằng chứng rằng rủi ro không còn ở mức giả định xa xôi. Khi một công ty phải xây ngưỡng đánh giá cho bio risk, cyber risk, autonomous misuse, reward hacking, deception, hay dangerous capability thresholds, thì điều đó nói lên rằng vấn đề đã đủ gần để phải vận hành hóa.
Nên khi nhìn biểu đồ thứ hai của Boaz, mình nghĩ thông điệp không phải là “alignment không tiến bộ”. Mà là:
alignment đang tiến bộ, nhưng chưa đủ nhanh để bắt kịp độ hệ trọng của những gì AI sắp được giao làm.
3. Tin tốt lớn nhất: chúng ta chưa thấy quá nhiều scheming rõ rệt
Trong 4 biểu đồ, đây là phần tinh tế nhất.
Boaz cho rằng một trong những tin tốt quan trọng nhất hiện nay là: chúng ta dường như chưa thấy quá nhiều dấu hiệu mạnh của scheming hoặc collusion ở models, và nhờ đó con người vẫn còn có thể dùng model để monitor model khác, hỗ trợ safety work, và cải thiện alignment tiếp. Ông xem đây là một trong những mẩu good news lớn nhất của AI safety hiện tại.
Hiểu một cách đơn giản, “scheming” là khi AI không chỉ trả lời sai theo kiểu ngây ngô, mà bắt đầu biết:
che giấu ý định
giả vờ ngoan khi bị đánh giá
tối ưu theo mục tiêu khác với mục tiêu con người nghĩ nó đang làm
hoặc biết qua mặt chính cơ chế kiểm tra
Đó là một dạng rủi ro nguy hiểm hơn hallucination bình thường rất nhiều, vì khi một hệ thống đủ giỏi để trông có vẻ aligned, thì việc đo nó có aligned thật hay không sẽ trở nên khó hơn hẳn. Đây cũng là lý do Anthropic dành hẳn không gian trong Claude 4 system card để thảo luận các đánh giá liên quan tới reward hacking và agentic safety trong coding/computer-use settings.
Nhưng chỗ đáng suy nghĩ là: “chưa thấy quá nhiều” không đồng nghĩa với “chuyện đó không thể xảy ra”. International AI Safety Report 2026 nhấn mạnh rằng general-purpose AI systems đang tiếp tục cải thiện ở nhiều năng lực cốt lõi, trong khi rủi ro đi kèm cần được quản lý bằng cả biện pháp kỹ thuật lẫn governance. Báo cáo không chỉ nhìn vào mô hình đơn lẻ, mà nhìn vào các rủi ro thực tiễn phát sinh khi khả năng của hệ thống tăng lên.
Yoshua Bengio thì đi xa hơn ở hướng “safe by design”. Dự án LawZero mà ông công bố năm 2026 nói rất rõ mục tiêu là xây các hệ thống non-agentic hơn, có cấu trúc “generator + neutral estimator”, nhằm giảm động cơ theo đuổi mục tiêu riêng từ bên trong hệ thống. Chỉ riêng việc một trong những tên tuổi lớn nhất của deep learning chuyển sang nhấn mạnh “safe by design” và “not desiring” cũng cho thấy một nỗi lo đang hiện hữu: nếu để các hệ thống ngày càng agentic hơn mà không giải được bài toán kiểm soát, thì giám sát từ bên ngoài có thể không đủ.
Tóm lại, biểu đồ thứ ba không phải để hù dọa rằng AI đã bắt đầu âm mưu. Nó nói điều ngược lại: may mắn là chúng ta chưa ở trạng thái xấu nhất. Nhưng nếu coi đó là lý do để chủ quan, thì lại là sai bài.
4. Điểm yếu nhất có thể không nằm ở model, mà nằm ở xã hội
Đây là phần mình thấy Boaz nói đúng và thật nhất.
Có một sự thật phũ phàng rằng xã hội chưa sẵn sàng cho AI, và cũng chưa cho thấy dấu hiệu đang sẵn sàng đủ nhanh. Điều này không chỉ nằm ở kỹ thuật. Nó là câu chuyện của:
luật pháp
tổ chức
giáo dục
thị trường lao động
an ninh sinh học và an ninh mạng
hợp tác quốc tế
và cả khả năng bảo vệ dân chủ, tự chủ cá nhân, thông tin công cộng trước những hệ thống ngày càng mạnh hơn
International AI Safety Report 2026 cũng đi theo đúng hướng này: báo cáo được viết với hơn 100 chuyên gia độc lập từ hơn 30 quốc gia và tổ chức quốc tế, và mục tiêu của nó không chỉ là mô tả risk, mà còn là đánh giá các cách quản lý risk. Chỉ riêng quy mô hợp tác đó đã cho thấy AI safety không còn là việc nội bộ của vài lab. Nó đã là một chủ đề governance ở cấp quốc tế.
Demis Hassabis trong các phát biểu công khai gần đây cũng lặp lại nhu cầu về một nỗ lực phối hợp quốc tế cho AI security và AI safety, theo hướng có thể so sánh với những định chế hợp tác lớn trong khoa học hoặc hạt nhân. Ở chiều khác, Dario Amodei gần đây tiếp tục cảnh báo rằng các hệ thống rất mạnh có thể đang đến gần, còn câu hỏi lớn là liệu các hệ thống của con người có sẵn sàng hấp thụ “quyền lực gần như khó tưởng tượng” đó hay không.
Mình nghĩ đây là chỗ rất đáng để người làm product, strategy, hay quản trị đọc kỹ. Vì nhiều khi chúng ta nói “AI safety” như thể đó là vấn đề của model lab. Nhưng nếu nhìn ở tầng vận hành thực, câu hỏi quan trọng hơn lại là:
công ty có governance model chưa?
có audit trail chưa?
có chính sách human oversight chưa?
có định nghĩa rõ context nào cho AI ra quyết định, context nào không?
có kịch bản incident response chưa?
có phương án reskill workforce chưa?
có chuẩn bị cho abuse, cyber misuse, hoặc information manipulation chưa?
Nói cách khác:
một model mạnh không tự động khiến tổ chức hay xã hội trưởng thành hơn để dùng nó.
Và nếu societal readiness là đường gần như nằm ngang, như Boaz vẽ, thì đó mới có thể là khoảng cách nguy hiểm nhất.
5. Tốc độ phát triển hiện tại khiến mọi thứ khó hơn theo cách nào?
Cái khó của giai đoạn này không nằm ở việc AI “mạnh lên” một cách tuyến tính. Cái khó là nhiều đường cong đang cùng lúc di chuyển:
capability tăng
chi phí giảm
khả năng phổ cập tăng
open models thu hẹp khoảng cách
agentic workflows tiến bộ
AI bắt đầu được dùng để tăng tốc chính việc phát triển AI
Đây là lý do vì sao Boaz nói nếu “squint” một chút, ta thậm chí có thể thấy đường capability đang có dấu hiệu bẻ lên khi AI được dùng để phát triển AI. Dario Amodei trong một bài viết khác cũng nhắc lại điểm này, liên hệ trực tiếp METR với việc AI đang tiến tới các task lấy của con người nhiều giờ làm việc hơn.
Với tốc độ như vậy, mọi cơ chế quản trị đều bị đặt dưới áp lực thời gian:
policy thường ra chậm hơn product cycle
luật thường đi sau deployment
giáo dục đi sau thị trường
chuẩn mực xã hội đi sau công nghệ
còn safety research thì vừa phải đuổi theo capability, vừa phải chứng minh giá trị trong một môi trường cạnh tranh cực nhanh
Chính vì vậy, câu hỏi thực tế của giai đoạn này không còn là “AI có mạnh không?” nữa. Câu hỏi đúng hơn là:
chúng ta có đang xây đủ nhanh những lớp kiểm soát, giám sát, và thể chế để hấp thụ sức mạnh đó hay không?
6. Điều mình rút ra: bài toán không còn là model safety, mà là system safety
Điều mình thích nhất ở bài của Boaz là nó không rơi vào hai thái cực quen thuộc.
Nó không bảo:
“mọi thứ ổn, cứ scale tiếp”
Nhưng nó cũng không bảo:
“ngày mai tận thế”
Nó là một bản chẩn đoán thực tế:
capability tăng rất nhanh
alignment có tiến bộ nhưng chưa đủ
chưa thấy scheming mạnh là một tin tốt
nhưng societal readiness có thể là điểm yếu lớn nhất
Và nếu phải nâng luận điểm này lên thêm một tầng, mình sẽ nói thế này:
AI safety bây giờ không còn chỉ là model safety. Nó là system safety.
Nó liên quan tới:
model behavior
deployment context
incentives của công ty
standards của ngành
governance của quốc gia
khả năng hợp tác quốc tế
và mức độ trưởng thành của xã hội trong việc sống chung với một loại trí tuệ ngày càng hữu dụng, nhưng cũng ngày càng khó xem nhẹ
Lời kết
Nếu phải tóm toàn bộ bài này bằng một câu, mình sẽ viết:
Chúng ta đang xây AI nhanh hơn tốc độ chúng ta học cách kiểm soát nó, và nhanh hơn cả tốc độ xã hội chuẩn bị để sống chung với nó.
Boaz dùng 4 biểu đồ vẽ tay để nói điều đó.
METR cho thấy tốc độ capability progress không phải chuyện tưởng tượng. Stanford AI Index cho thấy chi phí giảm và phổ cập tăng đang làm làn sóng này mạnh hơn nữa. Các framework của OpenAI, Anthropic, DeepMind cho thấy chính frontier labs cũng thừa nhận cần cơ chế kiểm soát bài bản hơn. Còn những tiếng nói như Bengio, Hassabis, Amodei thì dù khác nhau về nhấn mạnh, đều gặp nhau ở một điểm: AI safety không thể chỉ để cho thị trường hoặc tốc độ sản phẩm tự giải quyết.
Có lẽ câu hỏi quan trọng nhất ở thời điểm này không phải là:
AI mạnh tới đâu?
Mà là:
chúng ta đã nghiêm túc tới đâu với những thứ cần thiết để giữ quyền kiểm soát khi nó mạnh lên?
References
Barak, B. (2026). The state of AI safety in four fake graphs. Windows on Theory.
Maslej, N., et al. (2025). The 2025 AI Index Report. Stanford HAI.
Kwa, T., et al. (2025). Measuring AI Ability to Complete Long Tasks. METR / arXiv.
OpenAI. (2025). Our updated Preparedness Framework.
Anthropic. (2026). Anthropic’s Transparency Hub.
International AI Safety Report. (2026). International AI Safety Report 2026.